จากการเรียนในรายวิชาการเตรียมฝึกประสบการณ์วิชาชีพบริหารธุรกิจ 3 ทำให้ดิฉันได้รับความรู้ในด้านต่าง ๆ ที่ทำให้พร้อมที่จะออกไปฝึกประสบการณ์การทำงานนอกรั้วมหาวิทยาลัย ได้รับการอบรมอย่างดีจากอาจารย์และวิทยากรที่มีความรู้เฉพาะด้าน ได้แก่
1. เรื่องการมีคุณธรรมและจริยธรรมในการทำงานและการปฏิบัติตนทั้งต่อตนเองและต่อผู้อื่น
2. ฝึกให้มีความรับผิดชอบในงานที่ได้รับมอบหมาย และมีความซื่อสัตย์สุจริต
3. เรียนรู้เรื่องการเงิน การออม การบริหารเงินของตนเองในแต่ละเดือน
4. ได้ทบทวนความรู้ภาษาอังกฤษ และมีการทดสอบความรู้ภาษาอังกฤษ ซึ่งทำให้เราสามารถทราบได้ว่าความรู้ในด้านภาษาอังกฤษของเรามีมากน้อยเพียงใด
5. กิจกรรมการคัดไทย ทำให้เราฝึกในเรื่องการเขียน ซึ่งการเขียนเป็นสิ่งที่จำเป็นอย่างหนึ่งในการทำงาน และได้ทบทวนความรู้วิชาภาษาไทยที่จำเป็นในการประกอบอาชีพด้วย
6. มีการอบรมเรื่องการพัฒนาบุคลิกภาพ เช่น การแต่งกาย การแต่งหน้า ทำผม การปฏิบัติตนในที่สังคมต่าง ๆ มารยาทบนโต๊ะอาหาร เป็นต้น
7. ได้แนวคิดจากวิทยากรในเรื่องของการวางแผนการทำงานในชีวิต การสร้างกำลังใจให้กับตนเองในการดำเนินชีวิตประจำวัน
8. ได้รับประสบการณ์จากการคุมสอบ IT สามารถนำไปใช้ในอนาคตได้ เนื่องจากในการคุมสอบครั้งนี้ทำให้เราทราบถึงปัญหาและอุปสรรคที่อาจจะเกิดขึ้น ตลอดจนวิธีการแก้ปัญหาต่าง ๆ
9. ได้รับความรู้ในเรื่องของวัฒนธรรมของต่างชาติ การติดต่อธุรกิจกับนักธุรกิจประเทศต่าง ๆ และได้ทราบถึงลักษณะนิสัยของคนในหลาย ๆ ประเทศด้วย ซึ่งความรู้ในส่วนนี้ เราสามารถนำไปปรับใช้ได้เมื่อเรามีโอกาสได้ติดต่อธุรกิจกับชาวต่างชาติ
10. มีความรู้ในเรื่องของซอฟต์แวร์ต่าง ๆ มากขึ้น ทราบถึงช่องทางที่เราจะนำไปพัฒนาความรู้ในเรื่องของคอมพิวเตอร์ได้มากขึ้น
11. ได้รับทั้งความรักและความปราถนาดีจากอาจารย์ทุก ๆ ท่านที่ควบคุมในรายวิชานี้ เพราะท่านคอยให้คำปรึกษา ตักเตือน และแนะนำศิษย์ทุกคนให้ปฏิบัติในสิ่งที่ถูกที่ควร
12. ได้รับข้อคิดดี ๆ และความสนุกสนานจากพระอาจารย์ที่ได้เทศนาให้พวกเราฟังในสัปดาห์สุดท้ายของการเรียน
วันพฤหัสบดีที่ 15 ตุลาคม พ.ศ. 2552
วันพฤหัสบดีที่ 17 กันยายน พ.ศ. 2552
DTS11-16-09-2552
สรุปสิ่งที่ได้จากการเรียนเรื่อง SORTING (ต่อ)
การเรียงลำดับ (sorting) เป็นการจัดให้เป็นระเบียบ มีแบบแผน ช่วยให้การค้นหาสิ่งของหรือข้อมูล สามารถทำได้รวดเร็วและมีประสิทธิภาพการเรียงลำดับอย่างมีประสิทธิภาพหลักเกณฑ์ในการพิจารณาเพื่อเลือกวิธีการเรียงลำดับที่ดีและเหมาะสมกับระบบงาน
1.เวลาและแรงงานที่ต้องใช้ในการเขียนโปรแกรม
2.เวลาที่เครื่องคอมพิวเตอร์ต้องใช้ในการทำงานตามโปรแกรมที่เขียน
3.จำนวนเนื้อที่ในหน่วยความจำหลักมีเพียงพอหรือไม่วิธีการเรียงลำดับ มีหลายวิธีที่สามารถใช้ในการเรียงลำดับข้อมูลได้
วิธีการเรียงลำดับแบ่งออกเป็น 2 ประเภท
1.การเรียงลำดับภายใน (internal sorting) เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ในหน่วยความจำหลัก
2.การเรียงลำดับแบบภายนอก (external sorting) เป็นการเรียนลำดับข้อมูลที่เก็บอยู่ในหน่วยความจำสำรอง เป็นการเรียงลำดับข้อมูลในแฟ้มข้อมูล (file) การเรียงลำดับแบบเลือก (selection sort)ข้อมูลจะอยู่ทีละตัว โดยทำการค้นหาข้อมูลในแต่ละรอบแบบเรียงลำดับ ถ้าเป็นการเรียงลำดับจากน้อยไปมาก1.ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บไว้ที่ตำแหน่งที่ 12 ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่ตำแหน่งที่สองทำแบบนี้ไปเรื่อยๆ จนครบทุกค่า ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการการจัดเรียงลำดับแบบเลือกเป็นวิธีที่ง่ายและตรงไปตรงมา แต่มีข้อเสียตรงที่ใช้เวลาในการจัดเรียงนาน เพราะแต่ละรอบต้องเปรียบเอียบกับข้อมูลทุกตัว
3.การเรียงลำดับแบบฟอง (Bubble Sort)เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลในตำแหน่งที่อยู่ติดกัน
1.ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่งที่อยู่กัน
2.ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มีค่าน้อยกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก ถ้าเป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มีค่ามากกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่าน้อยการจัดเรียงลำดับแบบฟองเป็นวิธีที่ไม่ซับซ้อนมาก เป็นวิธีการเรียงลำดับที่นิยมใช้กันมากเพราะมีรูปแบบที่เข้าใจง่าย
การเรียงลำดับ (sorting) เป็นการจัดให้เป็นระเบียบ มีแบบแผน ช่วยให้การค้นหาสิ่งของหรือข้อมูล สามารถทำได้รวดเร็วและมีประสิทธิภาพการเรียงลำดับอย่างมีประสิทธิภาพหลักเกณฑ์ในการพิจารณาเพื่อเลือกวิธีการเรียงลำดับที่ดีและเหมาะสมกับระบบงาน
1.เวลาและแรงงานที่ต้องใช้ในการเขียนโปรแกรม
2.เวลาที่เครื่องคอมพิวเตอร์ต้องใช้ในการทำงานตามโปรแกรมที่เขียน
3.จำนวนเนื้อที่ในหน่วยความจำหลักมีเพียงพอหรือไม่วิธีการเรียงลำดับ มีหลายวิธีที่สามารถใช้ในการเรียงลำดับข้อมูลได้
วิธีการเรียงลำดับแบ่งออกเป็น 2 ประเภท
1.การเรียงลำดับภายใน (internal sorting) เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ในหน่วยความจำหลัก
2.การเรียงลำดับแบบภายนอก (external sorting) เป็นการเรียนลำดับข้อมูลที่เก็บอยู่ในหน่วยความจำสำรอง เป็นการเรียงลำดับข้อมูลในแฟ้มข้อมูล (file) การเรียงลำดับแบบเลือก (selection sort)ข้อมูลจะอยู่ทีละตัว โดยทำการค้นหาข้อมูลในแต่ละรอบแบบเรียงลำดับ ถ้าเป็นการเรียงลำดับจากน้อยไปมาก1.ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บไว้ที่ตำแหน่งที่ 12 ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่ตำแหน่งที่สองทำแบบนี้ไปเรื่อยๆ จนครบทุกค่า ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการการจัดเรียงลำดับแบบเลือกเป็นวิธีที่ง่ายและตรงไปตรงมา แต่มีข้อเสียตรงที่ใช้เวลาในการจัดเรียงนาน เพราะแต่ละรอบต้องเปรียบเอียบกับข้อมูลทุกตัว
3.การเรียงลำดับแบบฟอง (Bubble Sort)เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลในตำแหน่งที่อยู่ติดกัน
1.ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่งที่อยู่กัน
2.ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มีค่าน้อยกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก ถ้าเป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มีค่ามากกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่าน้อยการจัดเรียงลำดับแบบฟองเป็นวิธีที่ไม่ซับซ้อนมาก เป็นวิธีการเรียงลำดับที่นิยมใช้กันมากเพราะมีรูปแบบที่เข้าใจง่าย
วันเสาร์ที่ 12 กันยายน พ.ศ. 2552
DTS10-09-09-2552
สรุปสิ่งที่ได้รับในการเรียนเรื่อง SORTING
SORTING
การจัดเรียงข้อมูลนับเป็นสิ่งสำคัญที่ใช้ในการดำเนินการกับข้อมูลเพื่อประโยชน์ในการจัดการกับข้อมูล การค้นหา หรือการดำเนินการอย่างอื่นได้สะดวกและรวดเร็ว มากกว่าข้อมูลที่ไม่มีการจัดเรียง เช่น การจัดเรียงหนังสือในห้องสมุด การจัดเรียงคำศัพท์ในพจนานุกรม ระบบการจัดเรียงจะมีรูปแบบของการจัดเรียงที่แตกต่างกันไปตามความเหมาะสม และสำหรับรูปแบบของการจัดเรียงข้อมูลในคอมพิวเตอร์ก็มีหลากหลายรูปแบบที่ใช้ในการจัดเรียงข้อมูล ซึ่งรูปแบบที่กำหนดขึ้นมานั้นก็มีทั้งข้อดีและข้อเสียแตกต่างกันไปขึ้นอยู่กับการเลือกให้เหมาะสมกับข้อมูลแต่ละชนิด
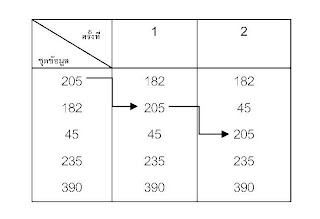 ข้อมูลที่ได้จากการจัดเรียงในรอบที่ 2 คือ 182 45 205 235 390 ซึ่งในรอบนี้จะเห็นว่าการเปรียบเทียบค่านั้นจะเปรียบเทียบเพียงแค่ 2 ครั้งเพราะค่าหลัง 205 นั้นมีค่ามากกว่าแล้วจึงไม่ดำเนินการต่อแต่ยังต้องเรียงลำดับข้อมูลต่อในรอบที่ 3
ข้อมูลที่ได้จากการจัดเรียงในรอบที่ 2 คือ 182 45 205 235 390 ซึ่งในรอบนี้จะเห็นว่าการเปรียบเทียบค่านั้นจะเปรียบเทียบเพียงแค่ 2 ครั้งเพราะค่าหลัง 205 นั้นมีค่ามากกว่าแล้วจึงไม่ดำเนินการต่อแต่ยังต้องเรียงลำดับข้อมูลต่อในรอบที่ 3 จากตารางเป็นการจัดเรียงข้อมูลแบบบับเบิ้ลในรอบที่ 3 ข้อมูลมีการจัดเรียงแบบบับเบิ้ลเสร็จ โดยเรียงจากน้อยไปหามากได้ข้อมูล 45 182 205 235 390 จะเห็นว่าใช้การจัดเรียงที่มีจำนวนครั้งในการจัดเรียงแต่ละรอบหลายครั้งกว่าจะได้ข้อมูลออกมา แต่ในบางรอบของการจัดเรียง ข้อมูลที่ได้มีการจัดเรียงถูกต้องแล้วก็จะไม่นำมาเปรียบเทียบค่าอีก
จากตารางเป็นการจัดเรียงข้อมูลแบบบับเบิ้ลในรอบที่ 3 ข้อมูลมีการจัดเรียงแบบบับเบิ้ลเสร็จ โดยเรียงจากน้อยไปหามากได้ข้อมูล 45 182 205 235 390 จะเห็นว่าใช้การจัดเรียงที่มีจำนวนครั้งในการจัดเรียงแต่ละรอบหลายครั้งกว่าจะได้ข้อมูลออกมา แต่ในบางรอบของการจัดเรียง ข้อมูลที่ได้มีการจัดเรียงถูกต้องแล้วก็จะไม่นำมาเปรียบเทียบค่าอีก
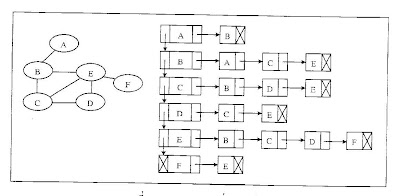
 จากภาพ แสดงการแบ่งพื้นที่ในการจัดเรียงข้อมูลจะกำหนดพื้นที่ส่วนหน้าเป็นพื้นที่จัดเรียงข้อมูล พื้นที่ส่วนหลังใช้ในการเก็บข้อมูลที่ยังไม่ได้จัดเรียง หากนำข้อมูลมาจากพื้นที่ด้านหลังก็จะนำมาแทรกยังตำแหน่งที่ถูกต้องด้านหน้า ซึ่งจะได้ข้อมูลการจัดเรียงแบบถูกต้องคือ 8 23 32 45 56 78
จากภาพ แสดงการแบ่งพื้นที่ในการจัดเรียงข้อมูลจะกำหนดพื้นที่ส่วนหน้าเป็นพื้นที่จัดเรียงข้อมูล พื้นที่ส่วนหลังใช้ในการเก็บข้อมูลที่ยังไม่ได้จัดเรียง หากนำข้อมูลมาจากพื้นที่ด้านหลังก็จะนำมาแทรกยังตำแหน่งที่ถูกต้องด้านหน้า ซึ่งจะได้ข้อมูลการจัดเรียงแบบถูกต้องคือ 8 23 32 45 56 78
SORTING
การจัดเรียงข้อมูลนับเป็นสิ่งสำคัญที่ใช้ในการดำเนินการกับข้อมูลเพื่อประโยชน์ในการจัดการกับข้อมูล การค้นหา หรือการดำเนินการอย่างอื่นได้สะดวกและรวดเร็ว มากกว่าข้อมูลที่ไม่มีการจัดเรียง เช่น การจัดเรียงหนังสือในห้องสมุด การจัดเรียงคำศัพท์ในพจนานุกรม ระบบการจัดเรียงจะมีรูปแบบของการจัดเรียงที่แตกต่างกันไปตามความเหมาะสม และสำหรับรูปแบบของการจัดเรียงข้อมูลในคอมพิวเตอร์ก็มีหลากหลายรูปแบบที่ใช้ในการจัดเรียงข้อมูล ซึ่งรูปแบบที่กำหนดขึ้นมานั้นก็มีทั้งข้อดีและข้อเสียแตกต่างกันไปขึ้นอยู่กับการเลือกให้เหมาะสมกับข้อมูลแต่ละชนิด
ประเภทของการจัดเรียงข้อมูล
การจัดเรียงข้อมูลมีรูปแบบที่หลากหลาย เพื่อให้เกิดประโยชน์ต่อการดำเนินการ แบ่งออกเป็น 2 ประเภท คือ 1. การจัดเรียงข้อมูลภายนอก (External Sorting) เป็นการกำหนดการโอนย้ายข้อมูลจากหน่วยความจำหลัก ไปเก็บไว้ในหน่วยความจำสำรอง เช่น แผ่นดิสก์, เทปแม่เหล็ก โดยการวัดประสิทธิภาพของการจัดเรียงข้อมูลนั้นจะวัดจากเวลาที่ใช้ในการโอนย้ายข้อมูล
2. การจัดเรียงข้อมูลภายใน (Internal Sorting) เป็นวิธีการที่จัดเรียงข้อมูลภายในหน่วยความจำหลัก ซึ่งจะต้องมีการจัดเรียงข้อมูลให้มีประสิทธิภาพมากที่สุด ดังนั้นจึงได้มีอัลกอริทึมที่หลากหลายเพื่อให้เลือกนำไปจัดเรียงกับข้อมูลในหน่วยความจำหลัก
การจัดเรียงข้อมูลมีรูปแบบที่หลากหลาย เพื่อให้เกิดประโยชน์ต่อการดำเนินการ แบ่งออกเป็น 2 ประเภท คือ 1. การจัดเรียงข้อมูลภายนอก (External Sorting) เป็นการกำหนดการโอนย้ายข้อมูลจากหน่วยความจำหลัก ไปเก็บไว้ในหน่วยความจำสำรอง เช่น แผ่นดิสก์, เทปแม่เหล็ก โดยการวัดประสิทธิภาพของการจัดเรียงข้อมูลนั้นจะวัดจากเวลาที่ใช้ในการโอนย้ายข้อมูล
2. การจัดเรียงข้อมูลภายใน (Internal Sorting) เป็นวิธีการที่จัดเรียงข้อมูลภายในหน่วยความจำหลัก ซึ่งจะต้องมีการจัดเรียงข้อมูลให้มีประสิทธิภาพมากที่สุด ดังนั้นจึงได้มีอัลกอริทึมที่หลากหลายเพื่อให้เลือกนำไปจัดเรียงกับข้อมูลในหน่วยความจำหลัก
การจัดเรียงข้อมูลแบบเบื้องต้น
1. การจัดเรียงข้อมูลแบบเลือก (Selection Sort) มีหลักการของการจัดเรียง คือ เลือกค่าข้อมูลที่น้อยหรือมากที่สุดอย่างใดอย่างหนึ่งในแต่ละฐานข้อมูลเป็นตัวหลัก จากนั้นนำมาจัดเรียงแบบลำดับเลือกข้อมูลตัวต่อไปจนจัดเรียงเสร็จ เช่น ข้อมูล 1 ชุด ประกอบด้วย 390 205 182 45 235 จากข้อมูลชุดนี้ หากนำมาจัดเรียงแบบเลือกจัดลำดับค่าต่ำสุดไปหาค่าสูงสุดได้ดังนี้ จากตารางแสดงการจัดเรียงข้อมูลแบบเลือกของชุดข้อมูลทั้ง 5 ตัวในแนวตั้ง คือ
จากตารางแสดงการจัดเรียงข้อมูลแบบเลือกของชุดข้อมูลทั้ง 5 ตัวในแนวตั้ง คือ
ครั้งที่ 1 เลือกข้อมูลที่มีค่าน้อยที่สุดมาจัดเรียงลำดับสลับตำแหน่งระหว่าง 45 และ 390
ครั้งที่ 2 เลือกข้อมูลที่น้อยลงมาเป็นอันดับที่ 2 คือ 182 ไปสลับกับ 205 ในตำแหน่งที่ 2
ครั้งที่ 3 เลือกข้อมูลที่น้อยลงมาเป็นอันดับที่ 3 คือ 205 ซึ่งอยู่ในตำแหน่งเดิม
ครั้งที่ 4 เลือกข้อมูลที่น้อยลงมาเป็นอันดับที่ 4 คือ 235 ไปสลับกับ 390 ในตำแหน่งที่ 4
จึงไม่มีครั้งที่ 5 เพราะข้อมูลได้มีการจัดเรียงลำดับครบทุกตัวแล้ว
2. การจัดเรียงข้อมูลแบบฟอง (Bubble Sort) เป็นรูปแบบของการจัดเรียงแบบแลกเปลี่ยนเนื่องจากลักษณะของการจัดเรียงจะใช้การเปรียบเทียบค่าใน 2 ตำแหน่งใกล้เคียงเรียงลำดับการจัดจากมากไปน้อยหรือจากน้อยไปมาก จากนั้นจะเปลี่ยนตำแหน่งกันแล้วใช้ตำแหน่งที่ 2 เปรียบเทียบกับตารางที่ 3 ไปจนถึงตำแหน่งที่ n จนเสร็จสิ้นการจัดเรียง เช่น จากข้อมูล 390 205 182 45 235 นำมาจัดเรียงแบบบับเบิ้ลได้ดังตาราง
 จากตารางแสดงการจัดเรียงข้อมูลแบบบับเบิ้ลในรอบที่ 1 ทำการเปรียบเทียบค่าแล้วเลื่อนค่าลงเปรียบเทียบกับตำแหน่งต่อไป ในรอบที่ 1 นี้จะทำการเปรียบเทียบอยู่ 4 ครั้ง คือ
จากตารางแสดงการจัดเรียงข้อมูลแบบบับเบิ้ลในรอบที่ 1 ทำการเปรียบเทียบค่าแล้วเลื่อนค่าลงเปรียบเทียบกับตำแหน่งต่อไป ในรอบที่ 1 นี้จะทำการเปรียบเทียบอยู่ 4 ครั้ง คือ
ครั้งที่ 1 เปรียบเทียบข้อมูลกับตำแหน่งที่ 1,2 ข้อมูล 390>205 เปลี่ยนตำแหน่ง 205 ไว้ด้านบน
ครั้งที่ 2 เปรียบเทียบข้อมูลกับตำแหน่งที่ 2,3 ข้อมูล 390>182 เปลี่ยนตำแหน่ง 182 ไว้ด้านบน
ครั้งที่ 3 เปรียบเทียบข้อมูลกับตำแหน่งที่ 3,4 ข้อมูล 390>45 เปลี่ยนตำแหน่ง 45 ไว้ด้านบน
ครั้งที่ 4 เปรียบเทียบข้อมูลกับตำแหน่งที่ 4,5 ข้อมูล 390>235 เปลี่ยนตำแหน่ง 235 ไว้ด้านบน
จะเห็นว่าข้อมูลที่จัดเรียงได้ค่า 205 182 45 235 390 ซึ่งยังไม่เสร็จสิ้น จึงต้องทำการเปรียบเทียบค่าอีกโดยใช้วิธีการเดิมในรอบที่ 2
ข้อมูลที่ได้จากการจัดเรียงในรอบที่ 2 คือ 182 45 205 235 390 ซึ่งในรอบนี้จะเห็นว่าการเปรียบเทียบค่านั้นจะเปรียบเทียบเพียงแค่ 2 ครั้งเพราะค่าหลัง 205 นั้นมีค่ามากกว่าแล้วจึงไม่ดำเนินการต่อแต่ยังต้องเรียงลำดับข้อมูลต่อในรอบที่ 3จากตารางเป็นการจัดเรียงข้อมูลแบบบับเบิ้ลในรอบที่ 3 ข้อมูลมีการจัดเรียงแบบบับเบิ้ลเสร็จ โดยเรียงจากน้อยไปหามากได้ข้อมูล 45 182 205 235 390 จะเห็นว่าใช้การจัดเรียงที่มีจำนวนครั้งในการจัดเรียงแต่ละรอบหลายครั้งกว่าจะได้ข้อมูลออกมา แต่ในบางรอบของการจัดเรียง ข้อมูลที่ได้มีการจัดเรียงถูกต้องแล้วก็จะไม่นำมาเปรียบเทียบค่าอีก 3. การจัดเรียงข้อมูลแบบแทรก (Insertion Sorting) จะใช้หลักการของการจัดเรียงที่ว่ากำหนดพื้นที่ออกเป็น 2 ส่วน ส่วนแรกใช้ในการจัดข้อมูลที่เรียงลำดับแล้วและอีกส่วนคือ ข้อมูลที่ยังไม่ได้จัดเรียง นำเอาข้อมูลที่ยังไม่ได้จัดเรียงมาแทรกยังตำแหน่งที่ถูกต้องด้านที่ใช้จัดเรียงลำดับ และดำเนินการต่อไปจนกว่าการจัดเรียงจะถูกต้อง เช่น ข้อมูลชุด 23 78 45 8 32 56 สามารถจัดเรียงได้ดังภาพ
จากภาพ แสดงการแบ่งพื้นที่ในการจัดเรียงข้อมูลจะกำหนดพื้นที่ส่วนหน้าเป็นพื้นที่จัดเรียงข้อมูล พื้นที่ส่วนหลังใช้ในการเก็บข้อมูลที่ยังไม่ได้จัดเรียง หากนำข้อมูลมาจากพื้นที่ด้านหลังก็จะนำมาแทรกยังตำแหน่งที่ถูกต้องด้านหน้า ซึ่งจะได้ข้อมูลการจัดเรียงแบบถูกต้องคือ 8 23 32 45 56 784. การจัดเรียงแบบฐาน (Radix Sort) เป็นการเรียงลำดับโดยการพิจารณาข้อมูลทีละหลัก มีหลักการคือ จะเริ่มพิจารณาจากหลักที่มีค่าน้อยที่สุดก่อน นั่นคือถ้าข้อมูลเป็นฐานเลขจำนวนเต็มจะพิจารณาหลักหน่วยก่อน การจัดเรียงจะนำข้อมูลเข้ามาทีละตัว แล้วนำไปเก็บไว้ในที่ซึ่งจัดไว้สำหรับค่านั้นเป็นกลุ่มๆ ตามลำดับเข้ามา ในแต่ละรอบเมื่อจัดกลุ่มเรียบร้อยแล้ว ให้รวบรวมข้อมูลจากทุกกลุ่มเข้าด้วยกัน โดยเริ่มเรียงจากกลุ่มที่มีค่าน้อยที่สุดก่อนแล้วเรียงไปเรื่อยๆ จนหมดทุกกลุ่ม และในรอบต่อไปนำข้อมูลทั้งหมดที่ได้จัดเรียงในหลักหน่วยเรียบร้อยแล้วมาพิจารณาจัดเรียงในหลักสิบต่อไป ทำเช่นนี้ไปเรื่อยๆ จนกระทั่งครบทุกหลัก จะได้ข้อมูลที่เรียงลำดับจากน้อยไปมากตามลำดับ
การเรียงลำดับแบบฐานมีวิธีการที่ไม่ซับซ้อน แต่ค่อนข้างใช้เนื้อที่ในหน่วยความจำมาก เนื่องจากการจัดเรียงแต่ละรอบจะต้องเตรียมเนื้อที่สำหรับสร้างที่เก็บข้อมูลในแต่ละกลุ่ม เช่น ถ้ามีจำนวนข้อมูล n ตัว และในแต่ละกลุ่มใช้วิธีจัดเก็บข้อมูลในแถวลำดับ ต้องกำหนดให้แต่ละกลุ่มมีสมาชิกได้ n ตัว เท่ากับจำนวนข้อมูล เผื่อไว้ในกรณีที่ข้อมูลทั้งหมดมีค่าในหลักนั้นๆ เหมือนกัน ถ้าเป็นเลขจำนวนใช้ทั้งหมด 10 กลุ่ม กลุ่มละ n ตัว รวมทั้งหมดมีขนาดเท่ากับ (10 x n)
วันพฤหัสบดีที่ 3 กันยายน พ.ศ. 2552
DTS09-02-09-2552
สรุปสิ่งที่ได้จากการเรียนเรื่อง TREE ( ต่อ )
EXPRESSION TREE
เป็นการนำเอาโครงสร้างทรีไปใช้เก็บนิพจน์ทางคณิตศาสตร์โดยเป็นไบนารีทรี ซึ่งตและโหนดเก็บ Operator และ Operand ของนิพจน์คณิตศาสตร์ไว้ หรืออาจจะเก็บค่านิพจน์ทางตรรกะ เมื่อแทนนิพจน์ต่างลงในทรีต้องคำนึงถึงลำดับขั้นตอนในการคำนวณตามความสำคัญของเครื่องหมายด้วย โดยมีความสำคัญ คือ ฟังก์ชัน วงเล็บ ยกกำลัง เครื่องหมายหน้าเลขจำนวน(unary) คูณหรือหาร บวกหรือลบ ตามลำดับ และถ้ามีเครื่องหมายที่ระดับเดียวกันให้ทำจากซ้ายไปขวา
ในการแทนนิพจน์ใน expression tree นั้น operand จะเก็บอยู่ที่โหนดใบ ส่วน operator จะเก็บในโหนดกิ่ง หรือโหนดที่ไม่ใช่โหนดใบ
BINARY SEARCH TREE
เป็นไบนารีทรีที่ค่าของโหนดรากมีค่ามากกว่าค่าของทุกโหนดในทรีย่อยทางซ้าย และมีค่าน้อยกว่าหรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวาและในแต่ละทรีย่อยก็จะมีคุณสมบัติเช่นเดียวกัน
ปฏิบัติการเพิ่มโหนดหรือดึงโหนดออกจาก Binary Search Tree ค่อนข้างยุ่งยาก เนื่องจากหลังปฏิบัติการเสร็จเรียบร้อยแล้วต้องคำนึงถึงความเป็น Binary Search Tree ของทรีนั้นด้วย ซึ่งสามารถทำได้ดังนี้
1. การเพิ่มโหนด ถ้าทรีว่างโหนดที่เพิ่มเข้าไปก็จะเป็นโหนดรากของทรี แต่ถ้าทรีไม่ว่างต้องทำการตรวจสอบก่อนว่าโหนดใหม่ที่เพิ่มเข้าไปมีค่ามากกว่าหรือน้อยกว่าโหนดราก ให้เปรียบเทียบตามคุณสมบัติที่กล่าวไว้ข้างต้น
2. การดึงโหนดออก ซึ่งหลังจากที่ดึงออกแล้วนั้นต้องคงความเป็น Binary Search Tree ไว้ ก่อนที่จะทำการดึงโหนดต้องค้นหาก่อนว่าโหนดที่ต้องการจะดึงออกอยู่ที่ตำแหน่งไหนภายในทรี สามารถพิจารณาได้เป็น 3 กรณีคือ
ก.) กรณี่เป็นโหนดใบ สามารถดึงออกได้เลยทันที โดยให้ค่าในลิงค์ฟิลด์ของโหนดแม่ซึ่งเก็บที่อยู่ของโหนดที่ต้องการดึงออกให้มีค่าเป็น Null
ข.) กรณีที่มีเฉพาะทรีย่อยทางซ้ายหรือทรีย่อยทางขวาเพียงด้านใดด้านหนึ่ง โดยใช้วิธีเดียวกับการดึงโหนดออกจากลิงค์ลิสต์ โดยให้โหนดแม่ของโหนดที่จะดึงออกชี้ไปยังโหนดลูกของโหนดนั้นแทน
ค.) กรณีที่มีทั้งทรีย่อยทางซ้ายและทางขวาต้องเลือกโหนดมาแทนโหนดที่ถูกดึงออก โดยถ้าโหนดที่มาแทนที่เป็นหนดที่เลือกจากทรีย่อยทางซ้ายต้องเลือกโหนดที่มีค่ามากที่สุดในทรีย่อยทางซ้ายนั้น แต่ถ้าเลือกโหนดจากทรีย่อยทางขวาต้องเลือกโหนดที่มีค่าน้อยที่สุดในทรีย่อยทางขวานั้น
GRAPH
เป็นโครงสร้างข้อมูลที่มีโครงสร้างประกอบไปด้วยโหนด (Vertixes) และการเชื่อมต่อ(Edges) ลักษณะการเชื่อมต่อจะแตกต่างจากโครงสร้างข้อมูลแบบอื่น ๆ คือ สามารถที่จะเชื่อมต่อแต่ละโหนดได้หลากหลาย และทิศทางของการเดินทางสามารถเชื่อมต่อได้หลากหลายเช่นกัน มีความสัมพันธ์ได้ทั้ง 2 แบบ คือ แบบไม่ระบุทิศทาง และแบบระบุทิศทาง ดังภาพ
การจัดเก็บกราฟด้วยวิธีการเก็บโหนดและพอยน์เตอร์ยุ่งยากในการจัดการเพิ่มขึ้น เนืองจากต้องเก็บโหนดและพอยน์เตอร์ในแถวลำดับ 2 มิติ และต้องจัดเก็บโหนดที่สัมพันธ์ด้วยในแถวลำดับ 1 มิติ และควรใช้ในกราฟที่ไม่มีการเปลี่ยนแปลงตลอดการใช้งาน
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา ควรใช้วิธี Adjacency List ซึ่งเป็นวิธีที่คล้ายวิธีการจัดเก็บกราฟแบบการเก็บโหนดและพอยน์เตอร์ แต่แตกต่างกันตรงที่จะใช้ลิงค์ลิสต์แทน เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข มีหลักคือ
- การแทนค่าแต่ละแถวของอะเรย์ 2 มิติจะกลายเป็นลิงค์ลิสต์
- หัวแถวจะเป็นโหนดของกราฟ จะมีเท่ากับจำนวนโหนด
- โหนดในแต่ละแถวคือ โหนดที่อยู่ข้างเคียงหรือเพื่อนบ้านของโหนดหัวแถว
ตัวอย่างเช่น
 การแทนที่กราฟด้วยเมทริกซ์ หรือ Adjacency Matrix เป็นโครงสร้างที่ประกอบไปด้วยโหนดและเส้นเชื่อมต่อที่บอกถึงเส้นทางของการเดินทาง หรือความสัมพันธ์ในทิศทางซึ่งสามารถนำมาแทนความสัมพันธ์นั้นด้วยการกำหนดเมตริกซ์ n x n
การแทนที่กราฟด้วยเมทริกซ์ หรือ Adjacency Matrix เป็นโครงสร้างที่ประกอบไปด้วยโหนดและเส้นเชื่อมต่อที่บอกถึงเส้นทางของการเดินทาง หรือความสัมพันธ์ในทิศทางซึ่งสามารถนำมาแทนความสัมพันธ์นั้นด้วยการกำหนดเมตริกซ์ n x n
ตัวอย่างเช่น
 สามารแทนที่กราฟแบบเมทริกซ์ได้ดังนี้
สามารแทนที่กราฟแบบเมทริกซ์ได้ดังนี้
EXPRESSION TREE
เป็นการนำเอาโครงสร้างทรีไปใช้เก็บนิพจน์ทางคณิตศาสตร์โดยเป็นไบนารีทรี ซึ่งตและโหนดเก็บ Operator และ Operand ของนิพจน์คณิตศาสตร์ไว้ หรืออาจจะเก็บค่านิพจน์ทางตรรกะ เมื่อแทนนิพจน์ต่างลงในทรีต้องคำนึงถึงลำดับขั้นตอนในการคำนวณตามความสำคัญของเครื่องหมายด้วย โดยมีความสำคัญ คือ ฟังก์ชัน วงเล็บ ยกกำลัง เครื่องหมายหน้าเลขจำนวน(unary) คูณหรือหาร บวกหรือลบ ตามลำดับ และถ้ามีเครื่องหมายที่ระดับเดียวกันให้ทำจากซ้ายไปขวา
ในการแทนนิพจน์ใน expression tree นั้น operand จะเก็บอยู่ที่โหนดใบ ส่วน operator จะเก็บในโหนดกิ่ง หรือโหนดที่ไม่ใช่โหนดใบ
BINARY SEARCH TREE
เป็นไบนารีทรีที่ค่าของโหนดรากมีค่ามากกว่าค่าของทุกโหนดในทรีย่อยทางซ้าย และมีค่าน้อยกว่าหรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวาและในแต่ละทรีย่อยก็จะมีคุณสมบัติเช่นเดียวกัน
ปฏิบัติการเพิ่มโหนดหรือดึงโหนดออกจาก Binary Search Tree ค่อนข้างยุ่งยาก เนื่องจากหลังปฏิบัติการเสร็จเรียบร้อยแล้วต้องคำนึงถึงความเป็น Binary Search Tree ของทรีนั้นด้วย ซึ่งสามารถทำได้ดังนี้
1. การเพิ่มโหนด ถ้าทรีว่างโหนดที่เพิ่มเข้าไปก็จะเป็นโหนดรากของทรี แต่ถ้าทรีไม่ว่างต้องทำการตรวจสอบก่อนว่าโหนดใหม่ที่เพิ่มเข้าไปมีค่ามากกว่าหรือน้อยกว่าโหนดราก ให้เปรียบเทียบตามคุณสมบัติที่กล่าวไว้ข้างต้น
2. การดึงโหนดออก ซึ่งหลังจากที่ดึงออกแล้วนั้นต้องคงความเป็น Binary Search Tree ไว้ ก่อนที่จะทำการดึงโหนดต้องค้นหาก่อนว่าโหนดที่ต้องการจะดึงออกอยู่ที่ตำแหน่งไหนภายในทรี สามารถพิจารณาได้เป็น 3 กรณีคือ
ก.) กรณี่เป็นโหนดใบ สามารถดึงออกได้เลยทันที โดยให้ค่าในลิงค์ฟิลด์ของโหนดแม่ซึ่งเก็บที่อยู่ของโหนดที่ต้องการดึงออกให้มีค่าเป็น Null
ข.) กรณีที่มีเฉพาะทรีย่อยทางซ้ายหรือทรีย่อยทางขวาเพียงด้านใดด้านหนึ่ง โดยใช้วิธีเดียวกับการดึงโหนดออกจากลิงค์ลิสต์ โดยให้โหนดแม่ของโหนดที่จะดึงออกชี้ไปยังโหนดลูกของโหนดนั้นแทน
ค.) กรณีที่มีทั้งทรีย่อยทางซ้ายและทางขวาต้องเลือกโหนดมาแทนโหนดที่ถูกดึงออก โดยถ้าโหนดที่มาแทนที่เป็นหนดที่เลือกจากทรีย่อยทางซ้ายต้องเลือกโหนดที่มีค่ามากที่สุดในทรีย่อยทางซ้ายนั้น แต่ถ้าเลือกโหนดจากทรีย่อยทางขวาต้องเลือกโหนดที่มีค่าน้อยที่สุดในทรีย่อยทางขวานั้น
GRAPH
เป็นโครงสร้างข้อมูลที่มีโครงสร้างประกอบไปด้วยโหนด (Vertixes) และการเชื่อมต่อ(Edges) ลักษณะการเชื่อมต่อจะแตกต่างจากโครงสร้างข้อมูลแบบอื่น ๆ คือ สามารถที่จะเชื่อมต่อแต่ละโหนดได้หลากหลาย และทิศทางของการเดินทางสามารถเชื่อมต่อได้หลากหลายเช่นกัน มีความสัมพันธ์ได้ทั้ง 2 แบบ คือ แบบไม่ระบุทิศทาง และแบบระบุทิศทาง ดังภาพ
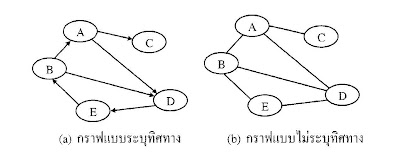 การเขียนกราฟแสดงโหนดและเส้นเชื่อมความสัมพันธ์ระหว่างโหนดไม่มีรูปแบบที่ตายตัว การลากเส้นความสัมพันธ์เป็นลักษณะใดก็ได้ที่สามารถแสดงความสัมพันธ์ระหว่างโหนดได้ถูกต้อง นอกจากนี้ เอ็จโหนดใด ๆ สามารถวนเข้าหาตัวมันเองได้
การเขียนกราฟแสดงโหนดและเส้นเชื่อมความสัมพันธ์ระหว่างโหนดไม่มีรูปแบบที่ตายตัว การลากเส้นความสัมพันธ์เป็นลักษณะใดก็ได้ที่สามารถแสดงความสัมพันธ์ระหว่างโหนดได้ถูกต้อง นอกจากนี้ เอ็จโหนดใด ๆ สามารถวนเข้าหาตัวมันเองได้
การจัดเก็บกราฟด้วยวิธีการเก็บโหนดและพอยน์เตอร์ยุ่งยากในการจัดการเพิ่มขึ้น เนืองจากต้องเก็บโหนดและพอยน์เตอร์ในแถวลำดับ 2 มิติ และต้องจัดเก็บโหนดที่สัมพันธ์ด้วยในแถวลำดับ 1 มิติ และควรใช้ในกราฟที่ไม่มีการเปลี่ยนแปลงตลอดการใช้งาน
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา ควรใช้วิธี Adjacency List ซึ่งเป็นวิธีที่คล้ายวิธีการจัดเก็บกราฟแบบการเก็บโหนดและพอยน์เตอร์ แต่แตกต่างกันตรงที่จะใช้ลิงค์ลิสต์แทน เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข มีหลักคือ
- การแทนค่าแต่ละแถวของอะเรย์ 2 มิติจะกลายเป็นลิงค์ลิสต์
- หัวแถวจะเป็นโหนดของกราฟ จะมีเท่ากับจำนวนโหนด
- โหนดในแต่ละแถวคือ โหนดที่อยู่ข้างเคียงหรือเพื่อนบ้านของโหนดหัวแถว
ตัวอย่างเช่น
การแทนที่กราฟด้วยเมทริกซ์ หรือ Adjacency Matrix เป็นโครงสร้างที่ประกอบไปด้วยโหนดและเส้นเชื่อมต่อที่บอกถึงเส้นทางของการเดินทาง หรือความสัมพันธ์ในทิศทางซึ่งสามารถนำมาแทนความสัมพันธ์นั้นด้วยการกำหนดเมตริกซ์ n x nตัวอย่างเช่น
สามารแทนที่กราฟแบบเมทริกซ์ได้ดังนี้ จากภาพ แทนที่เมทริกซ์ด้วยจำนวนโหนดทั้งแนวตั้งและแนวนอน โดยกำหนดให้แนวนอนเป็นโหนดต้นทางและแนวตั้งเป็นโหนดปลายทาง สามารถเขียนเลขลำดับเมทริกซ์โดยระบุค่า ดังนี้
จากภาพ แทนที่เมทริกซ์ด้วยจำนวนโหนดทั้งแนวตั้งและแนวนอน โดยกำหนดให้แนวนอนเป็นโหนดต้นทางและแนวตั้งเป็นโหนดปลายทาง สามารถเขียนเลขลำดับเมทริกซ์โดยระบุค่า ดังนี้
พิจารณาโหนด A มีเส้นเชื่อมต่อระบุไป B ระบุหมายเลย 1 นอกนั้นระบุค่าเป็น 0
พิจารณาโหนด B มีเส้นเชื่อมต่อระบุไป C, E ระบุหมายเลย 1 นอกนั้นระบุค่าเป็น 0
พิจารณาโหนด C มีเส้นเชื่อมต่อระบุไป D, E ระบุหมายเลย 1 นอกนั้นระบุค่าเป็น 0
พิจารณาโหนด D ไม่มีเส้นเชื่อมต่อไปยังโหนดอื่น B ระบุหมายเลข 0 ทุกช่อง
พิจารณาโหนด E มีเส้นเชื่อมต่อระบุไป D, F ระบุหมายเลย 1 นอกนั้นระบุค่าเป็น 0
พิจารณาโหนด F ไม่มีเส้นเชื่อมต่อไปยังโหนดอื่น B ระบุหมายเลข 0 ทุกช่อง
วันพุธที่ 26 สิงหาคม พ.ศ. 2552
DTS08-26-08-2552
สรุปสิ่งที่ได้จากการเรียน เรื่อง TREE
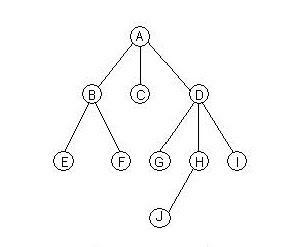
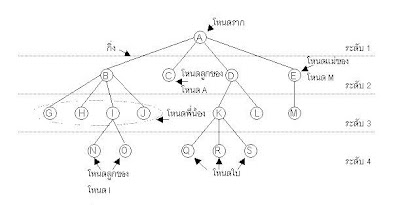 จากรูป อธิบายได้ว่า โหนด “A” คือโหนดรากของทรีนี้และเป็นโหนดแม่ของโหนด “B” “C” “D” และ “E” ขณะเดียวกันโหนด “B” “C” “D” และ “E” เป็นโหนดพี่น้องกันโดยทั้งหมดเป็นโหนดลูกของโหนด “A” โหนด “G” “H” “I” และ “J” เป็นโหนดพี่น้องกันเนื่องจากทั้งหมดเป็นโหนดลูกของโหนด “B” และโหนดที่ไม่มีลูกเลย เช่น โหนด “N” “O” “Q” “R” และ “S” ถือว่าเป็นโหนดใบ เป็นต้น
จากรูป อธิบายได้ว่า โหนด “A” คือโหนดรากของทรีนี้และเป็นโหนดแม่ของโหนด “B” “C” “D” และ “E” ขณะเดียวกันโหนด “B” “C” “D” และ “E” เป็นโหนดพี่น้องกันโดยทั้งหมดเป็นโหนดลูกของโหนด “A” โหนด “G” “H” “I” และ “J” เป็นโหนดพี่น้องกันเนื่องจากทั้งหมดเป็นโหนดลูกของโหนด “B” และโหนดที่ไม่มีลูกเลย เช่น โหนด “N” “O” “Q” “R” และ “S” ถือว่าเป็นโหนดใบ เป็นต้น
 2. "นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ" การกำหนดนิยามของ ทรีอาจกำหนดได้อีกวิธีหนึ่งเป็นการนิยามแบบรีเคอร์ซีฟ คือ ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่ ถ้าว่าง ไม่มีโหนดเลยเรียกว่า นัลทรี (null tree) และถ้ามีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือแบ่งเป็นทรีย่อย (sub tree) T1, T2, T3, ... , Tk (โดยที่ k³0) และทรีย่อยต้องมีคุณสมบัติเป็นทรี เช่นกัน
2. "นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ" การกำหนดนิยามของ ทรีอาจกำหนดได้อีกวิธีหนึ่งเป็นการนิยามแบบรีเคอร์ซีฟ คือ ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่ ถ้าว่าง ไม่มีโหนดเลยเรียกว่า นัลทรี (null tree) และถ้ามีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือแบ่งเป็นทรีย่อย (sub tree) T1, T2, T3, ... , Tk (โดยที่ k³0) และทรีย่อยต้องมีคุณสมบัติเป็นทรี เช่นกัน
 จากรูป แสดงตัวอย่างข้อมูลในโครงสร้างทรี ซึ่งมีโหนด “R” เป็นโหนดราก ที่ประกอบด้วย T1 , T2 และ T3 เป็นทรีย่อย และแต่ละทรีย่อยประกอบด้วยโหนดรากและทรีย่อยอีกเช่นกัน
จากรูป แสดงตัวอย่างข้อมูลในโครงสร้างทรี ซึ่งมีโหนด “R” เป็นโหนดราก ที่ประกอบด้วย T1 , T2 และ T3 เป็นทรีย่อย และแต่ละทรีย่อยประกอบด้วยโหนดรากและทรีย่อยอีกเช่นกัน
 จากภาพจะได้โครงสร้างทรีที่แต่ละโหนดมีลิงค์ฟิลด์แค่สองลิงค์ฟิลด์ ซึ่งช่วยให้ประหยัดเนื้อที่ในการจัดเก็บได้มาก เรียกโครงสร้างทรีที่แต่ละโหนดมีจำนวนโหนดลูกไม่เกินสองหรือแต่ละโหนดมีจำนวนทรีย่อยไม่เกินสองนี้ว่า "ไบนารีทรี" (binary tree) โดยเราอาจกล่าวไดัว่าการแทนที่ไบนารีทรีในหน่วยความจำ แต่ละโหนดประกอบด้วยลิงค์ฟิลด์สองลิงค์ฟิลด์ ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกทางซ้าย และลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดลูกทางขวา
จากภาพจะได้โครงสร้างทรีที่แต่ละโหนดมีลิงค์ฟิลด์แค่สองลิงค์ฟิลด์ ซึ่งช่วยให้ประหยัดเนื้อที่ในการจัดเก็บได้มาก เรียกโครงสร้างทรีที่แต่ละโหนดมีจำนวนโหนดลูกไม่เกินสองหรือแต่ละโหนดมีจำนวนทรีย่อยไม่เกินสองนี้ว่า "ไบนารีทรี" (binary tree) โดยเราอาจกล่าวไดัว่าการแทนที่ไบนารีทรีในหน่วยความจำ แต่ละโหนดประกอบด้วยลิงค์ฟิลด์สองลิงค์ฟิลด์ ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกทางซ้าย และลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดลูกทางขวา
 ไบนารีทรีที่ทุก ๆ โหนดมีทรีย่อยทางซ้ายและทรีย่อยทางขวา ยกเว้นโหนดใบ และโหนดใบทุกโหนดจะต้องอยู่ที่ระดับเดียวกันเรียกว่า "ไบนารีทรีแบบสมบูรณ์" (complete binary tree) ดังแสดงตัวอย่างทรีในภาพด้านบน เป็นไบนารีทรีแบบสมบูรณ์ที่มี 4 ระดับ เราสามารถคำนวณจำนวนโหนดทั้งหมดในไบนารีทรีแบบสมบูรณ์ได้ ถ้ากำหนดให้ L คือระดับของโหนดใด ๆ และ N คือจำนวนโหนดทั้งหมดในทรีจะได้ว่า
ไบนารีทรีที่ทุก ๆ โหนดมีทรีย่อยทางซ้ายและทรีย่อยทางขวา ยกเว้นโหนดใบ และโหนดใบทุกโหนดจะต้องอยู่ที่ระดับเดียวกันเรียกว่า "ไบนารีทรีแบบสมบูรณ์" (complete binary tree) ดังแสดงตัวอย่างทรีในภาพด้านบน เป็นไบนารีทรีแบบสมบูรณ์ที่มี 4 ระดับ เราสามารถคำนวณจำนวนโหนดทั้งหมดในไบนารีทรีแบบสมบูรณ์ได้ ถ้ากำหนดให้ L คือระดับของโหนดใด ๆ และ N คือจำนวนโหนดทั้งหมดในทรีจะได้ว่า
ระดับ 1 มีจำนวนโหนด 1 โหนด
ระดับ 2 มีจำนวนโหนด 3 โหนด
ระดับ 3 มีจำนวนโหนด 7 โหนด
ระดับ 4 มีจำนวนโหนด 15 โหนด
.
.
ระดับ L มีจำนวนโหนด 2L – 1 โหนด
เนื่องจากแต่ละโหนดมีโหนดลูกไม่เกิน 2 โหนด ดังนั้นการแทนทรีในหน่วยความจำเราอาจจะแทนโหนด ๆ หนึ่งด้วยโหนดที่มีฟิลด์ 3 ฟิลด์ ฟิลด์ที่หนึ่งสำหรับข้อมูล อีกสองฟิลด์เป็นลิงค์ฟิลด์สำหรับเก็บที่อยู่ของโหนดลูกทางซ้ายและโหนดลูกทางขวา และต้องมีพอยน์เตอร์เก็บที่อยู่ของโหนดรากไว้ด้วยเพื่อเป็นจุดเริ่มต้นของปฏิบัติการในทรี การแทนทรีในหน่วยความจำเราสามารถแทนในโครงสร้างแบบสแตติกซึ่งใช้แถวลำดับ หรือแทนในโครงสร้างแบบไดนามิกซึ่งใช้ข้อมูลแบบพอยน์เตอร์ ก็ได้
 ขั้นตอนการแปลง มีดังนี้
ขั้นตอนการแปลง มีดังนี้

 การท่องไปในไบนารีทรี
การท่องไปในไบนารีทรี
ปฏิบัติการที่สำคัญในไบนารีทรี คือ การท่องไปในไบนารีทรี (traversing binary tree) เพื่อเข้าไปเยือนทุก ๆ โหนดในทรี ซึ่งวิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบแผน สามารถเยือนโหนดทุก ๆ โหนด ๆ ละหนึ่งครั้ง วิธีการท่องไปนั้นมีด้วยกันหลายแบบแล้วแต่ว่าต้องการลำดับขั้นตอนการเยือนอย่างไรในการเยือนแต่ละครั้ง โหนดที่ถูกเยือนอาจเป็นโหนดแม่ (แทนด้วย N) ทรีย่อยทางซ้าย (แทนด้วย L) หรือทรีย่อยทางขวา (แทนด้วย R) มีวิธีการท่องเข้าไปในทรี 6 วิธี คือ NLR LNR LRN NRL RNL และ RLN แต่วิธีการท่องเข้าไปไบนารีทรีที่นิยมใช้กันมากเป็นการท่องจากซ้ายไปขวา 3 แบบแรกเท่านั้นซึ่งลักษณะการนิยามเป็นนิยามแบบรีเคอร์ซีฟ (recursive) ซึ่งขั้นตอนการท่องไปในแต่ละแบบมีดังนี้
1. "การท่องไปแบบพรีออร์เดอร์" (preorder traversal) เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี NLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์
ดังภาพ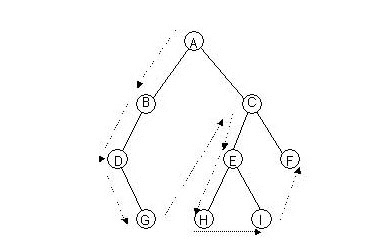 ท่องแบบพรีออร์เดอร์ (NLR) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ ABDGCEHIF
ท่องแบบพรีออร์เดอร์ (NLR) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ ABDGCEHIF
2. "การท่องไปแบบอินออร์เดอร์" (inorder traversal) เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี LNR ซึ่งมีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
ดังภาพ
 ท่องแบบโพสออร์เดอร์ (LRN) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ GDBHIEFCA
ท่องแบบโพสออร์เดอร์ (LRN) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ GDBHIEFCA
TREE
ทรี (tree) เป็นโครงสร้างข้อมูลที่ความสัมพันธ์ระหว่างโหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับชั้น (hierarchical relationship) มีกี่ชั้นก็ได้แล้วแต่งาน ได้มีการนำรูปแบบทรีไปประยุกต์ใช้ในงานต่าง ๆ อย่างแพร่หลาย ส่วนมากจะใช้สำหรับแสดงความสัมพันธ์ระหว่างข้อมูล ตัวอย่างที่มีการใช้โครงสร้างข้อมูลแบบทรี เช่น แผนผังแสดงองค์ประกอบของหน่วยงานต่าง ๆ โครงสร้างสารบัญหนังสือ และโครงสร้างแสดงสารบบในหน่วยความจำสำรองในเครื่องคอมพิวเตอร์ เป็นต้น
โดยทั่วไปแต่ละโหนดในทรีจะมีความสัมพันธ์กับโหนดในระดับที่ต่ำลงมาหนึ่งระดับได้หลาย ๆ โหนด หรืออาจกล่าวได้ว่าแต่ละโหนดของทรีเป็น "โหนดแม่" (parent or mother node) ของ "โหนดลูก" (child or son node) ซึ่งเป็นโหนดที่อยู่ในระดับต่ำลงมาหนึ่งระดับโดยสามารถมีโหนดลูกได้หลาย ๆ โหนด และโหนดต่าง ๆ ที่มีโหนดแม่เป็นโหนดเดียวกันเรียกว่า "โหนดพี่น้อง" (siblings) ทุก ๆ โหนดต้องมีโหนดแม่เสมอยกเว้นโหนดในระดับสูงสุดไม่มีโหนดแม่เรียกโหนดนี้ว่า "โหนดราก" (root node) โหนดที่ไม่มีโหนดลูกเลยเรียกว่า "โหนดใบ" (leave node) และเส้นเชื่อมแสดงความสัมพันธ์ระหว่างโหนดสองโหนดเรียกว่า "กิ่ง" (branch) สังเกตได้จากตัวอย่าง แสดงระดับของทรีและส่วนต่าง ๆ ของทรี
จากรูป อธิบายได้ว่า โหนด “A” คือโหนดรากของทรีนี้และเป็นโหนดแม่ของโหนด “B” “C” “D” และ “E” ขณะเดียวกันโหนด “B” “C” “D” และ “E” เป็นโหนดพี่น้องกันโดยทั้งหมดเป็นโหนดลูกของโหนด “A” โหนด “G” “H” “I” และ “J” เป็นโหนดพี่น้องกันเนื่องจากทั้งหมดเป็นโหนดลูกของโหนด “B” และโหนดที่ไม่มีลูกเลย เช่น โหนด “N” “O” “Q” “R” และ “S” ถือว่าเป็นโหนดใบ เป็นต้นนิยามของ TREE
1. "นิยามทรีด้วยนิยามของกราฟ" เนื่องจากรูปแบบของทรี เป็นรูปแบบเฉพาะอย่างหนึ่งของกราฟ (graph) ดังนั้นเราอาจจะกำหนดนิยามของทรีด้วยนิยามของกราฟดังนี้
ทรี คือ กราฟที่ต่อเนื่องกันโดยไม่มีวงจรปิด (loop) ในโครงสร้าง โหนดสองโหนดใด ๆ ในทรีต้องมีทางติดต่อกันทางเดียวเท่านั้น ทรีที่มี N โหนด ต้องมีกิ่งทั้งหมด N-1 เส้น การเขียนรูปแบบทรีอาจเขียนได้ 4 แบบ คือ
ทรี คือ กราฟที่ต่อเนื่องกันโดยไม่มีวงจรปิด (loop) ในโครงสร้าง โหนดสองโหนดใด ๆ ในทรีต้องมีทางติดต่อกันทางเดียวเท่านั้น ทรีที่มี N โหนด ต้องมีกิ่งทั้งหมด N-1 เส้น การเขียนรูปแบบทรีอาจเขียนได้ 4 แบบ คือ
2. "นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ" การกำหนดนิยามของ ทรีอาจกำหนดได้อีกวิธีหนึ่งเป็นการนิยามแบบรีเคอร์ซีฟ คือ ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่ ถ้าว่าง ไม่มีโหนดเลยเรียกว่า นัลทรี (null tree) และถ้ามีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือแบ่งเป็นทรีย่อย (sub tree) T1, T2, T3, ... , Tk (โดยที่ k³0) และทรีย่อยต้องมีคุณสมบัติเป็นทรี เช่นกันจากรูป แสดงตัวอย่างข้อมูลในโครงสร้างทรี ซึ่งมีโหนด “R” เป็นโหนดราก ที่ประกอบด้วย T1 , T2 และ T3 เป็นทรีย่อย และแต่ละทรีย่อยประกอบด้วยโหนดรากและทรีย่อยอีกเช่นกันนิยามที่เกี่ยวข้องกับ TREE มีนิยามต่าง ๆ ที่เกี่ยวข้องกับ ทรีมากมายดังต่อไปนี้
1. "ฟอร์เรสต์" (forest) หมายถึง กลุ่มของทรีที่เกิดจากการเอาโหนดรากของทรีออก หรือเซตของทรีที่แยกจากกัน (disjoint trees) เช่น ทรีในภาพด้านบน ถ้าตัดเอาโหนดราก “R” และตัดเส้นทางจากโหนด “R” ไปยัง โหนด “A” โหนด “B” และโหนด “C” ออกไปจากทรี ได้สามทรีย่อยที่แยกจากกันเรียกทั้งหมดว่า "ฟอร์เรสต์" ดังแสดงในภาพ
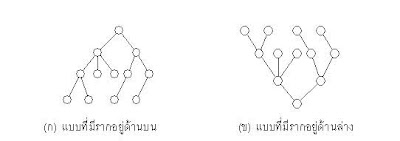
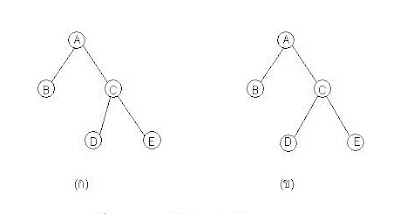
 (2) "ทรีที่มีแบบแผน" (ordered tree) หมายถึง ทรีที่โหนดต่าง ๆ ในทรีนั้นมีความสัมพันธ์ที่แน่นอน เช่น ก่อน ไปทางขวา ไปทางซ้าย เป็นต้น ทรีในภาพ (ก) และทรีในภาพ (ข) ด้านล่าง ถ้ากำหนดความสัมพันธ์ระหว่างโหนดไว้ถือว่า ทรีทั้งสองเป็นทรีที่ต่างกัน เนื่องจากทรีในภาพ (ก) โหนด “C” เป็นโหนดทางขวา ในขณะที่ ทรีในภาพ (ข) โหนด “C” เป็นโหนดทางซ้ายทำให้ทรีทั้งสองไม่เหมือนกัน และถ้าไม่ได้กำหนดความสัมพันธ์ระหว่างโหนดไว้ถือว่าทรีทั้งสองเป็นทรีที่เหมือนกัน เพราะมีจำนวนโหนดและจำนวนทรีย่อยเท่ากัน
(2) "ทรีที่มีแบบแผน" (ordered tree) หมายถึง ทรีที่โหนดต่าง ๆ ในทรีนั้นมีความสัมพันธ์ที่แน่นอน เช่น ก่อน ไปทางขวา ไปทางซ้าย เป็นต้น ทรีในภาพ (ก) และทรีในภาพ (ข) ด้านล่าง ถ้ากำหนดความสัมพันธ์ระหว่างโหนดไว้ถือว่า ทรีทั้งสองเป็นทรีที่ต่างกัน เนื่องจากทรีในภาพ (ก) โหนด “C” เป็นโหนดทางขวา ในขณะที่ ทรีในภาพ (ข) โหนด “C” เป็นโหนดทางซ้ายทำให้ทรีทั้งสองไม่เหมือนกัน และถ้าไม่ได้กำหนดความสัมพันธ์ระหว่างโหนดไว้ถือว่าทรีทั้งสองเป็นทรีที่เหมือนกัน เพราะมีจำนวนโหนดและจำนวนทรีย่อยเท่ากัน
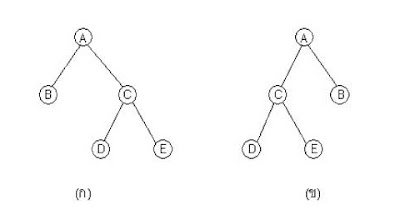 (3) "ทรีคล้าย" (similar tree) คือ ทรีที่มีโครงสร้างเหมือนกัน หรือทรีที่มีรูปร่างของทรีเหมือนกันนั่นเองโดยไม่คำนึงถึงข้อมูลที่อยู่ในแต่ละโหนด ตัวอย่าง ทรีในภาพ (ก) และ (ข) ด้านล่าง เป็นทรีที่คล้ายกันแต่ไม่เหมือนกัน เนื่องจากมีโครงสร้างทรีเหมือนกันแต่ข้อมูลในโหนดต่าง ๆ ที่ตำแหน่งเดียวกันไม่เหมือนกัน
(3) "ทรีคล้าย" (similar tree) คือ ทรีที่มีโครงสร้างเหมือนกัน หรือทรีที่มีรูปร่างของทรีเหมือนกันนั่นเองโดยไม่คำนึงถึงข้อมูลที่อยู่ในแต่ละโหนด ตัวอย่าง ทรีในภาพ (ก) และ (ข) ด้านล่าง เป็นทรีที่คล้ายกันแต่ไม่เหมือนกัน เนื่องจากมีโครงสร้างทรีเหมือนกันแต่ข้อมูลในโหนดต่าง ๆ ที่ตำแหน่งเดียวกันไม่เหมือนกัน
 (4) "ทรีเหมือน" (equivalent tree) หมายถึง ทรีที่เหมือนกันโดยสมบูรณ์ (equivalence) โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน ตัวอย่างทรีในภาพ (ก) และ (ข) ด้านล่าง ทรีทั้งสองเป็นทรีที่เหมือนกันเนื่องจากมีโครงสร้างทรีที่เหมือนกัน และในแต่ละโหนดที่ตำแหน่งเดียวกันมีข้อมูลเหมือนกัน
(4) "ทรีเหมือน" (equivalent tree) หมายถึง ทรีที่เหมือนกันโดยสมบูรณ์ (equivalence) โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน ตัวอย่างทรีในภาพ (ก) และ (ข) ด้านล่าง ทรีทั้งสองเป็นทรีที่เหมือนกันเนื่องจากมีโครงสร้างทรีที่เหมือนกัน และในแต่ละโหนดที่ตำแหน่งเดียวกันมีข้อมูลเหมือนกัน
 (5) "กำลัง" (degree) หมายถึง จำนวนทรีย่อยของโหนดนั้น ๆ ตัวอย่างทรีในภาพด้านล่าง โหนด “B” มีค่ากำลังเป็น 1 เพราะมีทรีย่อยคือ {“D”} ส่วนโหนด “C” มีค่ากำลังเป็น 2 เพราะมีทรีย่อย {“E”, “G”, “H”, “I”} และ {“F”} จะเห็นว่าโหนดใบเป็นโหนดที่ไม่มีทรีย่อยเลย ดังนั้นโหนดใบทุกโหนดมีค่ากำลังเป็นศูนย์
(5) "กำลัง" (degree) หมายถึง จำนวนทรีย่อยของโหนดนั้น ๆ ตัวอย่างทรีในภาพด้านล่าง โหนด “B” มีค่ากำลังเป็น 1 เพราะมีทรีย่อยคือ {“D”} ส่วนโหนด “C” มีค่ากำลังเป็น 2 เพราะมีทรีย่อย {“E”, “G”, “H”, “I”} และ {“F”} จะเห็นว่าโหนดใบเป็นโหนดที่ไม่มีทรีย่อยเลย ดังนั้นโหนดใบทุกโหนดมีค่ากำลังเป็นศูนย์
 (6) "ระดับของโหนด" (level of node) คือ ระยะทางในแนวดิ่งของโหนดนั้น ๆ ที่อยู่ห่างจากโหนดราก เมื่อกำหนดให้โหนดรากของทรีนั้นอยู่ที่ระดับ 1 และกิ่งแต่ละกิ่งมีความเท่ากันหมดคือยาวเท่ากับ 1 หน่วย ซึ่งระดับของโหนดจะเท่ากับจำนวนกิ่งที่น้อยที่สุดจากโหนดรากไปยังโหนดใด ๆ บวกด้วย 1 เช่น โหนด “H” ของทรีในภาพด้านล่าง มีระดับเป็น 4 เป็นต้น และจำนวนเส้นทางตามแนวดิ่งของโหนดใด ๆ ซึ่งห่างจากโหนดรากเรียกว่า ความสูง (height) หรือ ความลึก (depth) เช่น โหนด D มีความลึกเป็น 2 เป็นต้น
(6) "ระดับของโหนด" (level of node) คือ ระยะทางในแนวดิ่งของโหนดนั้น ๆ ที่อยู่ห่างจากโหนดราก เมื่อกำหนดให้โหนดรากของทรีนั้นอยู่ที่ระดับ 1 และกิ่งแต่ละกิ่งมีความเท่ากันหมดคือยาวเท่ากับ 1 หน่วย ซึ่งระดับของโหนดจะเท่ากับจำนวนกิ่งที่น้อยที่สุดจากโหนดรากไปยังโหนดใด ๆ บวกด้วย 1 เช่น โหนด “H” ของทรีในภาพด้านล่าง มีระดับเป็น 4 เป็นต้น และจำนวนเส้นทางตามแนวดิ่งของโหนดใด ๆ ซึ่งห่างจากโหนดรากเรียกว่า ความสูง (height) หรือ ความลึก (depth) เช่น โหนด D มีความลึกเป็น 2 เป็นต้น

(2) "ทรีที่มีแบบแผน" (ordered tree) หมายถึง ทรีที่โหนดต่าง ๆ ในทรีนั้นมีความสัมพันธ์ที่แน่นอน เช่น ก่อน ไปทางขวา ไปทางซ้าย เป็นต้น ทรีในภาพ (ก) และทรีในภาพ (ข) ด้านล่าง ถ้ากำหนดความสัมพันธ์ระหว่างโหนดไว้ถือว่า ทรีทั้งสองเป็นทรีที่ต่างกัน เนื่องจากทรีในภาพ (ก) โหนด “C” เป็นโหนดทางขวา ในขณะที่ ทรีในภาพ (ข) โหนด “C” เป็นโหนดทางซ้ายทำให้ทรีทั้งสองไม่เหมือนกัน และถ้าไม่ได้กำหนดความสัมพันธ์ระหว่างโหนดไว้ถือว่าทรีทั้งสองเป็นทรีที่เหมือนกัน เพราะมีจำนวนโหนดและจำนวนทรีย่อยเท่ากัน(3) "ทรีคล้าย" (similar tree) คือ ทรีที่มีโครงสร้างเหมือนกัน หรือทรีที่มีรูปร่างของทรีเหมือนกันนั่นเองโดยไม่คำนึงถึงข้อมูลที่อยู่ในแต่ละโหนด ตัวอย่าง ทรีในภาพ (ก) และ (ข) ด้านล่าง เป็นทรีที่คล้ายกันแต่ไม่เหมือนกัน เนื่องจากมีโครงสร้างทรีเหมือนกันแต่ข้อมูลในโหนดต่าง ๆ ที่ตำแหน่งเดียวกันไม่เหมือนกัน(4) "ทรีเหมือน" (equivalent tree) หมายถึง ทรีที่เหมือนกันโดยสมบูรณ์ (equivalence) โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน ตัวอย่างทรีในภาพ (ก) และ (ข) ด้านล่าง ทรีทั้งสองเป็นทรีที่เหมือนกันเนื่องจากมีโครงสร้างทรีที่เหมือนกัน และในแต่ละโหนดที่ตำแหน่งเดียวกันมีข้อมูลเหมือนกัน(5) "กำลัง" (degree) หมายถึง จำนวนทรีย่อยของโหนดนั้น ๆ ตัวอย่างทรีในภาพด้านล่าง โหนด “B” มีค่ากำลังเป็น 1 เพราะมีทรีย่อยคือ {“D”} ส่วนโหนด “C” มีค่ากำลังเป็น 2 เพราะมีทรีย่อย {“E”, “G”, “H”, “I”} และ {“F”} จะเห็นว่าโหนดใบเป็นโหนดที่ไม่มีทรีย่อยเลย ดังนั้นโหนดใบทุกโหนดมีค่ากำลังเป็นศูนย์(6) "ระดับของโหนด" (level of node) คือ ระยะทางในแนวดิ่งของโหนดนั้น ๆ ที่อยู่ห่างจากโหนดราก เมื่อกำหนดให้โหนดรากของทรีนั้นอยู่ที่ระดับ 1 และกิ่งแต่ละกิ่งมีความเท่ากันหมดคือยาวเท่ากับ 1 หน่วย ซึ่งระดับของโหนดจะเท่ากับจำนวนกิ่งที่น้อยที่สุดจากโหนดรากไปยังโหนดใด ๆ บวกด้วย 1 เช่น โหนด “H” ของทรีในภาพด้านล่าง มีระดับเป็น 4 เป็นต้น และจำนวนเส้นทางตามแนวดิ่งของโหนดใด ๆ ซึ่งห่างจากโหนดรากเรียกว่า ความสูง (height) หรือ ความลึก (depth) เช่น โหนด D มีความลึกเป็น 2 เป็นต้นการแทนที่ทรีในหน่วยความจำหลัก
การแทนที่โครงสร้างข้อมูลแบบทรีในความจำหลักสามารถแทนที่แบบสแตติก หรือแบบไดนามิกก็ได้ โดยมีพอยน์เตอร์เชื่อมโยงจากโหนดแม่ไปยังโหนดลูก แต่ละโหนดต้องมีลิงค์ฟิลด์หลายลิงค์ฟิลด์เพื่อเก็บที่อยู่ของโหนดลูกต่าง ๆ นั่นคือ จำนวนลิงค์ฟิลด์ของแต่ละโหนดขึ้นอยู่กับจำนวนของโหนดลูก การแทนที่ทรีซึ่งแต่ละโหนดมีจำนวนลิงค์ฟิลด์ไม่เท่ากัน ทำให้ยากต่อการปฏิบัติการเป็นอย่างยิ่ง มีวิธีการแทนที่ทรีในหน่วยความจำหลายวิธี วิธีที่ง่ายที่สุดคือทำให้แต่ละโหนดมีจำนวนลิงค์ฟิลด์เท่ากัน โดยอาจจะใช้วิธีการต่อไปนี้
1. แต่ละโหนดเก็บพอยน์เตอร์ชี้ไปยังโหนดลูกทุกโหนด การแทนที่ทรีในหน่วยความจำวิธีนี้ จะให้จำนวนฟิลด์ในแต่ละโหนดเท่ากัน โดยกำหนดจำนวนลิงค์ฟิลด์ทุกโหนดมีขนาดเท่ากับจำนวนโหนดลูกของโหนดที่มีลูกมากที่สุด โหนดใดไม่มีโหนดลูกก็ให้ค่าพอยน์เตอร์ในลิงค์ฟิลด์นั้น ๆ มีค่าเป็น NULL โดยให้ลิงค์ฟิลด์แรกเก็บค่าพอยน์เตอร์ชี้ไปยังโหนดลูกลำดับที่หนึ่ง ลิงค์ฟิลด์ที่สองเก็บค่าพอยน์เตอร์ชี้ไปยังโหนดลูกในลำดับที่สอง และลิงค์ฟิลด์อื่นเก็บค่าพอยน์เตอร์ของโหนดลูกในลำดับถัดไปเรื่อย ๆ
การแทนทรีด้วยโหนดขนาดเท่ากันค่อนข้างใช้เนื้อที่จำนวนมาก เนื่องจากแต่ละโหนดมีจำนวนโหนดลูกไม่เท่ากันหรือบางโหนดไม่มีโหนดลูกเลย ถ้าเป็นทรีที่แต่ละโหนดมีจำนวนโหนดลูกที่แตกต่างกันมาก เช่น ทรีที่มีบางโหนดมีจำนวนโหนดลูกสูงสุดเป็น 15 โหนด ในขณะที่โหนดอื่น ๆ ส่วนใหญ่มีจำนวนโหนดลูกแค่ 1 ถึง 2 โหนดเท่านั้น เราจะต้องกำหนดให้แต่ละโหนดมีลิงค์ฟิลด์ทั้งหมดเป็น 15 ลิงค์ฟิลด์ ทั้ง ๆ ที่ลิงค์ฟิลด์ส่วนใหญ่มีค่าเป็นนัล ทำให้ลิงค์ฟิลด์บางลิงค์ฟิลด์ไม่ได้ใช้ประโยชน์เลย เป็นการสิ้นเปลืองเนื้อที่ในหน่วยความจำโดยเปล่าประโยชน์
2. แทนทรีด้วยไบนารีทรี วิธีแก้ปัญหาเพื่อลดการสิ้นเปลืองเนื้อที่ในหน่วยความจำก็คือกำหนดลิงค์ฟิลด์ให้มีจำนวนน้อยที่สุดเท่าที่จำเป็นเท่านั้น ถ้ากำหนดให้แต่ละโหนดมีจำนวนลิงค์ฟิลด์สองลิงค์ฟิลด์ โดยให้ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกคนโต และลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดพี่น้องที่เป็นโหนดถัดไป โหนดใดไม่มีโหนดลูกหรือไม่มีโหนดพี่น้องให้ค่าพอยน์เตอร์ในลิงค์ฟิลด์มีค่าเป็น NULL
จากภาพจะได้โครงสร้างทรีที่แต่ละโหนดมีลิงค์ฟิลด์แค่สองลิงค์ฟิลด์ ซึ่งช่วยให้ประหยัดเนื้อที่ในการจัดเก็บได้มาก เรียกโครงสร้างทรีที่แต่ละโหนดมีจำนวนโหนดลูกไม่เกินสองหรือแต่ละโหนดมีจำนวนทรีย่อยไม่เกินสองนี้ว่า "ไบนารีทรี" (binary tree) โดยเราอาจกล่าวไดัว่าการแทนที่ไบนารีทรีในหน่วยความจำ แต่ละโหนดประกอบด้วยลิงค์ฟิลด์สองลิงค์ฟิลด์ ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกทางซ้าย และลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดลูกทางขวาไบนารีทรีที่ทุก ๆ โหนดมีทรีย่อยทางซ้ายและทรีย่อยทางขวา ยกเว้นโหนดใบ และโหนดใบทุกโหนดจะต้องอยู่ที่ระดับเดียวกันเรียกว่า "ไบนารีทรีแบบสมบูรณ์" (complete binary tree) ดังแสดงตัวอย่างทรีในภาพด้านบน เป็นไบนารีทรีแบบสมบูรณ์ที่มี 4 ระดับ เราสามารถคำนวณจำนวนโหนดทั้งหมดในไบนารีทรีแบบสมบูรณ์ได้ ถ้ากำหนดให้ L คือระดับของโหนดใด ๆ และ N คือจำนวนโหนดทั้งหมดในทรีจะได้ว่าระดับ 1 มีจำนวนโหนด 1 โหนด
ระดับ 2 มีจำนวนโหนด 3 โหนด
ระดับ 3 มีจำนวนโหนด 7 โหนด
ระดับ 4 มีจำนวนโหนด 15 โหนด
.
.
ระดับ L มีจำนวนโหนด 2L – 1 โหนด
เนื่องจากแต่ละโหนดมีโหนดลูกไม่เกิน 2 โหนด ดังนั้นการแทนทรีในหน่วยความจำเราอาจจะแทนโหนด ๆ หนึ่งด้วยโหนดที่มีฟิลด์ 3 ฟิลด์ ฟิลด์ที่หนึ่งสำหรับข้อมูล อีกสองฟิลด์เป็นลิงค์ฟิลด์สำหรับเก็บที่อยู่ของโหนดลูกทางซ้ายและโหนดลูกทางขวา และต้องมีพอยน์เตอร์เก็บที่อยู่ของโหนดรากไว้ด้วยเพื่อเป็นจุดเริ่มต้นของปฏิบัติการในทรี การแทนทรีในหน่วยความจำเราสามารถแทนในโครงสร้างแบบสแตติกซึ่งใช้แถวลำดับ หรือแทนในโครงสร้างแบบไดนามิกซึ่งใช้ข้อมูลแบบพอยน์เตอร์ ก็ได้
การแปลงไบนารีทั่วไปให้เป็นไบนารีทรี
ขั้นตอนการแปลงทรีทั่ว ๆ ไปให้เป็นไบนารีทรี ที่ความสัมพันธ์ของการจัดเก็บเหมือนกับที่กล่าวมาแล้วข้างต้น นั่นคือ แต่ละโหนดมี 2 ลิงค์ฟิลด์ ค่าพอยน์เตอร์ในลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกคนโต และค่าพอยน์เตอร์ในลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดพี่น้องคนถัดไป มีลำดับขั้นตอนการแปลงดังต่อไปนี้
(1) ให้โหนดแม่ชี้ไปยังโหนดลูกคนโต แล้วลบความสัมพันธ์ระหว่างโหนดแม่และโหนดลูกอื่น ๆ
(2) ให้เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
(3) จับให้ทรีย่อยทางขวาเอียงลงมา 45 องศา
(1) ให้โหนดแม่ชี้ไปยังโหนดลูกคนโต แล้วลบความสัมพันธ์ระหว่างโหนดแม่และโหนดลูกอื่น ๆ
(2) ให้เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
(3) จับให้ทรีย่อยทางขวาเอียงลงมา 45 องศา
ดังตัวอย่าง การแสดงขั้นตอนการแปลงทรีทั่วไปในภาพให้เป็นไบนารีทรี
ขั้นตอนการแปลง มีดังนี้การท่องไปในไบนารีทรีปฏิบัติการที่สำคัญในไบนารีทรี คือ การท่องไปในไบนารีทรี (traversing binary tree) เพื่อเข้าไปเยือนทุก ๆ โหนดในทรี ซึ่งวิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบแผน สามารถเยือนโหนดทุก ๆ โหนด ๆ ละหนึ่งครั้ง วิธีการท่องไปนั้นมีด้วยกันหลายแบบแล้วแต่ว่าต้องการลำดับขั้นตอนการเยือนอย่างไรในการเยือนแต่ละครั้ง โหนดที่ถูกเยือนอาจเป็นโหนดแม่ (แทนด้วย N) ทรีย่อยทางซ้าย (แทนด้วย L) หรือทรีย่อยทางขวา (แทนด้วย R) มีวิธีการท่องเข้าไปในทรี 6 วิธี คือ NLR LNR LRN NRL RNL และ RLN แต่วิธีการท่องเข้าไปไบนารีทรีที่นิยมใช้กันมากเป็นการท่องจากซ้ายไปขวา 3 แบบแรกเท่านั้นซึ่งลักษณะการนิยามเป็นนิยามแบบรีเคอร์ซีฟ (recursive) ซึ่งขั้นตอนการท่องไปในแต่ละแบบมีดังนี้
1. "การท่องไปแบบพรีออร์เดอร์" (preorder traversal) เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี NLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์
ดังภาพ
ท่องแบบพรีออร์เดอร์ (NLR) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ ABDGCEHIF2. "การท่องไปแบบอินออร์เดอร์" (inorder traversal) เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี LNR ซึ่งมีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
ดังภาพ
 ท่องแบบอินออร์เดอร์ (LNR) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ DGBAHEICF
ท่องแบบอินออร์เดอร์ (LNR) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ DGBAHEICF
3. "การท่องไปแบบโพสออร์เดอร์" (postorder traversal) เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรี ด้วยวิธี LRN ซึ่งมีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบโพสออร์เดอร์
(2) ท่องไปในทรีย่อยทางขวาแบบโพสออร์เดอร์
(3) เยือนโหนดราก
ดังภาพ
ท่องแบบโพสออร์เดอร์ (LRN) ผลลัพธ์จากการเยือนโหนดต่าง ๆ ดังนี้ GDBHIEFCA
วันพฤหัสบดีที่ 6 สิงหาคม พ.ศ. 2552
DTS07-05-08-2552
สรุปสิ่งที่ได้จากการเรียน เรื่อง Queue
 การดำเนินการพื้นฐานของ Queue ได้แก่
การดำเนินการพื้นฐานของ Queue ได้แก่
- การนำข้อมูลเข้าสู่ Queue เรียกว่า enqueue
- การนำข้อมูลออกจาก Queue เรียกว่า dequeue
- การนำข้อมูลที่อยู่ตอนต้นของ Queue มาแสดง เรียกว่า queue front
 ขั้นที่ 3
ขั้นที่ 3
 ขั้นที่ 4
ขั้นที่ 4
 ขั้นที่ 5
ขั้นที่ 5 ขั้นที่ 6
ขั้นที่ 6 การนำข้อมูลออกจากโครงสร้างคิว (dequeue)
การนำข้อมูลออกจากโครงสร้างคิว (dequeue)
เป็นการลบข้อมูลออกจากโครงสร้างคิวทางด้านหน้า ของโครงสร้างคิว โดยมีพอยน์เตอร์ F เป็นพอยน์เตอร์ชี้บอกตำแหน่งที่ข้อมูลอยู่ เมื่อมีการลบข้อมูล ออกจากโครงสร้างคิวเรียบร้อยแล้ว พอยน์เตอร์ F จะเลื่อนตำแหน่ง ไปยังตำแหน่งถัดไป
ข้อควรคำนึงถึง คือ เมื่อคิวว่าง (Empty queue) หรือไม่มีข้อมูลเหลืออยู่ จะไม่สามารถนำข้อมูลออกจากคิวได้อีก ซึ่ง จะทำให้เกิดปัญหา “underflow” ขึ้น
 ขั้นที่ 2
ขั้นที่ 2 ขั้นที่ 3
ขั้นที่ 3 ขั้นที่ 4
ขั้นที่ 4 ขั้นที่ 5
ขั้นที่ 5
 ขั้นที่ 6
ขั้นที่ 6 การแสดงข้อมูลตอนต้นของคิว (Queue Front)
การแสดงข้อมูลตอนต้นของคิว (Queue Front)

Queue
เป็นโครงสร้างข้อมูลแบบเชิงเส้นหรือลิเนียร์ลิสต์ ซึ่งมีลักษณะที่ว่า ข้อมูลที่นำเข้าไปเก็บก่อนจะถูกนำออกมาทำงานก่อน ส่วนข้อมูลที่เข้าไปเก็บทีหลังก็จะถูกนำออกมาใช้งานทีหลัง ขึ้นอยู่กับลำดับการเก็บข้อมูล จะ
เป็นโครงสร้างข้อมูลแบบเชิงเส้นหรือลิเนียร์ลิสต์ ซึ่งมีลักษณะที่ว่า ข้อมูลที่นำเข้าไปเก็บก่อนจะถูกนำออกมาทำงานก่อน ส่วนข้อมูลที่เข้าไปเก็บทีหลังก็จะถูกนำออกมาใช้งานทีหลัง ขึ้นอยู่กับลำดับการเก็บข้อมูล จะ
เรียกลักษณะการทำงานแบบนี้ว่า เข้าก่อนออกก่อน หรือ First In First Out (FIFO) มีข้อกำหนดให้ชุดปฏิบัติการสามารถเพิ่มค่าเข้าไปในตอนท้ายของรายการเพียงด้านเดียว เรียกว่า ส่วนหลัง ( Rear ) และลบค่าในตอนต้นของรายการเพียงด้านเดียว เรียกว่า ส่วนหน้า ( Front )
การดำเนินการพื้นฐานของ Queue ได้แก่- การนำข้อมูลเข้าสู่ Queue เรียกว่า enqueue
- การนำข้อมูลออกจาก Queue เรียกว่า dequeue
- การนำข้อมูลที่อยู่ตอนต้นของ Queue มาแสดง เรียกว่า queue front
- การนำข้อมูลที่อยู่ตอนท้ายของ Queue มาแสดง เรียกว่า queue rear
การนำข้อมูลเข้าสู่โครงสร้างคิว (enqueue)
เป็นกระบวนการอ่านข้อมูลจากภายนอกเข้าสู่โครงสร้างคิวทางด้านปลายที่พอยน์เตอร์ R ชี้อยู่ โดยพอยน์เตอร์ R จะเปลี่ยนตำแหน่ง ชี้ไปยังตำแหน่งที่ว่างตำแหน่งถัดไป ก่อนนำข้อมูลเข้าสู่โครงสร้างคิว
ข้อควรคำนึงถึง คือ ในขณะที่คิวเต็ม (Full Queues) หรือไม่มีช่องว่างเหลืออยู่ จะไม่สามารถนำข้อมูลเข้าไปเก็บในโครงสร้างคิวได้อีก ซึ่งจะทำให้เกิดปัญหา “Overflow” ขึ้น
ข้อควรคำนึงถึง คือ ในขณะที่คิวเต็ม (Full Queues) หรือไม่มีช่องว่างเหลืออยู่ จะไม่สามารถนำข้อมูลเข้าไปเก็บในโครงสร้างคิวได้อีก ซึ่งจะทำให้เกิดปัญหา “Overflow” ขึ้น
"ขั้นตอนการนำข้อมูลเข้าสู่โครงสร้างคิว" มีดังนี้
1. เมื่อมีข้อมูลเข้าสู่คิว ให้ตรวจสอบว่าคิวเต็มหรือไม่ ถ้าคิวเต็มไม่ให้มีการรับข้อมูล
2. ถ้าคิวไม่เต็มให้เลื่อนตำแหน่งพอยน์เตอร์ R แล้วนำข้อมูลเข้าสู่คิว
3. ตรวจสอบเงื่อนไขว่าถ้าเป็นข้อมูลตัวแรกในคิว ให้เปลี่ยนพอยน์เตอร์ F ให้ชี้ค่าแรก
1. เมื่อมีข้อมูลเข้าสู่คิว ให้ตรวจสอบว่าคิวเต็มหรือไม่ ถ้าคิวเต็มไม่ให้มีการรับข้อมูล
2. ถ้าคิวไม่เต็มให้เลื่อนตำแหน่งพอยน์เตอร์ R แล้วนำข้อมูลเข้าสู่คิว
3. ตรวจสอบเงื่อนไขว่าถ้าเป็นข้อมูลตัวแรกในคิว ให้เปลี่ยนพอยน์เตอร์ F ให้ชี้ค่าแรก
ตัวอย่างการนำข้อมูลเข้าสู่คิว (enqueue)
ขั้นที่ 1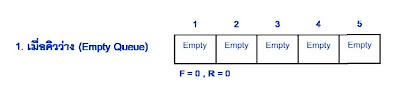 ขั้นที่ 2
ขั้นที่ 2
ขั้นที่ 2ขั้นที่ 3ขั้นที่ 4ขั้นที่ 5ขั้นที่ 6การนำข้อมูลออกจากโครงสร้างคิว (dequeue)เป็นการลบข้อมูลออกจากโครงสร้างคิวทางด้านหน้า ของโครงสร้างคิว โดยมีพอยน์เตอร์ F เป็นพอยน์เตอร์ชี้บอกตำแหน่งที่ข้อมูลอยู่ เมื่อมีการลบข้อมูล ออกจากโครงสร้างคิวเรียบร้อยแล้ว พอยน์เตอร์ F จะเลื่อนตำแหน่ง ไปยังตำแหน่งถัดไป
ข้อควรคำนึงถึง คือ เมื่อคิวว่าง (Empty queue) หรือไม่มีข้อมูลเหลืออยู่ จะไม่สามารถนำข้อมูลออกจากคิวได้อีก ซึ่ง จะทำให้เกิดปัญหา “underflow” ขึ้น
"ขั้นตอนการนำข้อมูลออกจากโครงสร้างคิว" มีดังนี้
1. ตรวจสอบว่าเป็นคิวว่าง (Empty Queues) หรือไม่
2. ถ้าคิวไม่ว่างให้นำข้อข้อมูลออกจากคิว ณ ตำแหน่งที่ F ชี้อยู่ จากนั้นก็ทำการเลื่อนตำแหน่งพอยน์เตอร์ F ไปยังตำแหน่งถัดไป
3. ถ้ามีข้อมูลอยู่เพียงตัวเดียว ให้กำหนดให้พอยน์เตอร์ F และ R เป็นศูนย์ (0)
1. ตรวจสอบว่าเป็นคิวว่าง (Empty Queues) หรือไม่
2. ถ้าคิวไม่ว่างให้นำข้อข้อมูลออกจากคิว ณ ตำแหน่งที่ F ชี้อยู่ จากนั้นก็ทำการเลื่อนตำแหน่งพอยน์เตอร์ F ไปยังตำแหน่งถัดไป
3. ถ้ามีข้อมูลอยู่เพียงตัวเดียว ให้กำหนดให้พอยน์เตอร์ F และ R เป็นศูนย์ (0)
ตัวอย่างการนำข้อมูลออกจากคิว (dequeue)
ขั้นที่ 1
ขั้นที่ 2 ขั้นที่ 3 ขั้นที่ 4 ขั้นที่ 5ขั้นที่ 6การแสดงข้อมูลตอนต้นของคิว (Queue Front)เป็นการนำข้อมูลที่อยู่ตอนต้นของคิวมาแสดง แต่จะไม่มีการเอาข้อมูลออกจากคิว ซึ่งประโยชน์ของมันก็คือ สามารถทำให้เรารู้ว่า คิวถัดไป (next queue) คืออะไร
การแสดงข้อมูลตอนท้ายของคิว (Queue Rear)
เป็นการนำข้อมูลที่อยู่ตอนท้ายของคิวมาแสดง แต่จะไม่ทำการเพิ่มข้อมูลเข้าไปในคิว ซึ่งประโยชน์ของมันก็คือ สามารถทหให้เรารู้ว่าลำดับสุดท้ายคืออะไร ลำดับที่เท่าไร
การแทนที่ข้อมูลของคิว สามารถทำได้ 2 วิธี คือ
1. การแทนที่ข้อมูลของคิวแบบลิงค์ลิสต์ ประกอบไปด้วย 2 ส่วน คือ Head Node ได้แก่ Front, Rear และจำนวนสมาชิกในคิว และ Data Node ได้แก่ ข้อมูล และพอยน์เตอร์ที่ชี้ไปยังข้อมูลตัวถัดไป
การดำเนินการเกี่ยวกับคิว ได้แก่
1.) Create Queue เป็นการจัดสรรหน่วยความจำให้กับ Head Node และให้ค่า pointer ทั้ง 2 ตัวมีค่าป็น null และจำนวนสมาชิกเป็นศูนย์
2.) Enqueue เป็นการเพิ่มข้อมูลเข้าไปในคิว ซึ่ง pointer rear จะเปลี่ยน
3.) Dequeue เป็นการนำข้อมูลออกจากคิว ซึ่ง pointer front จะเปลี่ยน
4.) Queue Front เป็นการนำข้อมูลที่อยู่ตอนต้นของคิวมาแสดง
5.) Queue Rear เป็นการนำข้อมูลที่อยู่ส่วนท้ายของคิวมาแสดง
6.) Empty Queue เป็นการตรวจสอบว่าคิวว่างหรือไม่
7.) Full Queue เป็นการตรวจสอบว่าคิวเต็มหรือไม่
8.) Queue Count เป็นการนับจำนวนสมาชิกที่อยู่ในคิว
9.) Destroy Queue เป็นการลบข้อมูลทั้งหมดที่อยู่ในคิว วิธีการคือ ต้องทำการ Dequeue ทีละตัว แล้วจึงจะ Destroy
2. การแทนที่ข้อมูลของคิวแบบอะเรย์
จากการดำเนินการกับโครงสร้างคิวจะเห็นได้ว่า โครงสร้างคิวยังไม่มีประสิทธิภาพเพียงใดนัก เนื่องจากเมื่อมีการเพิ่มข้อมูลจนเต็ม (Full Queue) และมีการลบข้อมูลออกจากโครงสร้างคิวแล้ว พอยน์เตอร์ F จะยังคงอยู่ที่ตำแหน่งเดิม ไม่สามารถเปลี่ยนไปที่ตำแหน่งเริ่มต้นใหม่ได้จนกว่าจะมีการลบข้อมูลออกจากคิวหมดแล้ว (Empty Queue) จึงจะสามารถกำหนดพอยน์เตอร์ข้อมูล F และ R ให้กลับไปยังตำแหน่งเริ่มต้นใหม่ได้ ทำให้เสียพื้นที่ของโครงสร้างคิวในตำแหน่งที่พอยน์เตอร์ F ผ่านมา ไปเนื่องจากต้องรอให้ตำแหน่งของพอยน์เตอร์ F ไปยังตำแหน่งสุดท้ายก่อน (เมื่อคิวว่าง) จึงจะสามารถใช้พื้นที่ดังกล่าวได้
จากสาเหตุดังกล่าวมาแล้ว จึงได้มีการพัฒนาโครงสร้างคิวให้มีความยืดหยุ่นมากขึ้น สามารถใช้งานพื้นที่โครงสร้างคิวได้อย่างเต็มประสิทธิภาพ โดยการนำปลายทางของโครงสร้าง คือ ด้านหน้าของโครงสร้าง (Front) และด้านหลังของโครงสร้าง (Rear) มาเชื่อมต่อกันในลักษณะวงกลม เรียกว่า คิววงกลม (Circular Queue)
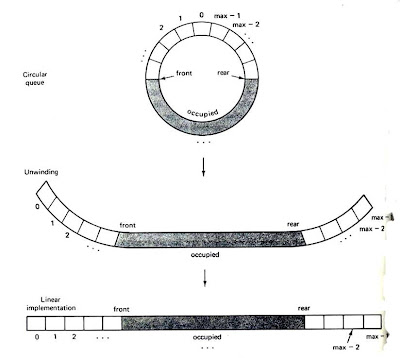 ในกรณีที่เป็นคิวแบบวงกลม คิวจะเต็มก็ต่อเมื่อมีการเพิ่มข้อมูลเข้าไปในคิวเรื่อยๆ จนกระทั่ง rear มีค่าน้อยกว่า front อยู่ 1 ค่า คือ rear = front - 1
ในกรณีที่เป็นคิวแบบวงกลม คิวจะเต็มก็ต่อเมื่อมีการเพิ่มข้อมูลเข้าไปในคิวเรื่อยๆ จนกระทั่ง rear มีค่าน้อยกว่า front อยู่ 1 ค่า คือ rear = front - 1
ลักษณะโครงสร้างของคิวแบบวงกลม
ในกรณีที่เป็นคิวแบบวงกลม คิวจะเต็มก็ต่อเมื่อมีการเพิ่มข้อมูลเข้าไปในคิวเรื่อยๆ จนกระทั่ง rear มีค่าน้อยกว่า front อยู่ 1 ค่า คือ rear = front - 1การประยุกต์ใช้คิว
- ใช้ในระบบปฏิบัติการ เช่น การจัดคิวโปรเซสเข้าใช้ซีพียู การจัดคิวงานพิมพ์
- ใช้ในเราเตอร์ เช่น การจัดคิวให้กับแต่ละ packet ก่อนส่งเข้าสาย
- ใช้ในเราเตอร์ เช่น การจัดคิวให้กับแต่ละ packet ก่อนส่งเข้าสาย
- ใช้ในการให้บีการลูกค้า คืด ต้องวิเคราะห์จำนวนลูกค้าในคิวที่เหมาะสม ว่าควรเป็นเท่าใด เพื่อให้ลูกค้าเสียเวลาน้อยที่สุด
- การเขียนโปรแกรมเพื่อจำลองแบบของสนามบิน จะใช้โครงสร้างข้อมูลแบบคิว แทนคิวของเครื่องบิน ที่จะรอขึ้นหรือรอลง แต่ค่อนข้างเป็นโปรแกรมที่ซับซ้อน ดังสภาพความเป็นจริงที่ว่า " สนามบินมีขนาดเล็กแต่มีเครื่องบินขึ้นลงจนวนมาก มีทางวิ่ง(runway)เพียงทางเดียว ณ เวลาใดๆ เครื่องบิน จะขึ้นหรือจะลงสามารถเป็นไปได้กรณีเดียวเท่านั้น และเพียงครั้งละเครื่องเดียวด้วย เครื่องบินที่มาถึงสนามบิน พร้อมที่จะขึ้นหรือลง ณ เวลาใด ๆ ก็ได้ ดังนั้น ณ เวลาใด ๆ ทางวิ่งอาจจะว่างหรืออาจจะมีเครื่องบินกำลังขึ้น หรือลงอยู่ก็ได้ และอาจจะมีเครื่องบินหลายลำที่รอขึ้นและรอลง จึงมีคิว 2 คิวคือคิวขึ้น(takeoff ) และคิวลง(landing)เครื่องเหล่านั้น หากว่าการรอนั้นบนพื้นดินจะดีกว่าบนอากาศ สนามบินขนาดเล็กจึงต้อง มีการให้เครื่องบินขึ้นต่อเมื่อไม่มีเครื่องบินลง หลังจากได้รับสัญญาณร้องขอจากเครื่องบินลำใหม่เพื่อจะลงหรือขึ้น" โปรแกรมการจำลองแบบจะให้บริการเครื่องบินที่อยู่ในตำแหน่งหัวคิวของคิวรอลงก่อนและถ้าคิวที่รอลงว่าง จึงอนุญาตให้เครื่องบินรอขึ้นขึ้นได้ โปรแกรมจำลองแบบนี้สามารถจะทำงานได้ตลอดเวลา
วันจันทร์ที่ 3 สิงหาคม พ.ศ. 2552
DTS06-29-07-2552
สรุปสิ่งที่ได้จากการเรียน เรื่อง Stack (ต่อ)
การแทนที่ข้อมูลของแสตก ทำได้ 2 วิธี คือ
 2. Data Node ประกอบด้วย Data และ Pointer ที่ชี้ไปยังข้อมูลตัวต่อไป
2. Data Node ประกอบด้วย Data และ Pointer ที่ชี้ไปยังข้อมูลตัวต่อไป
 การดำเนินการเกี่ยวกับสแตก
การดำเนินการเกี่ยวกับสแตก
 จากภาพ อธิบายได้ว่าในสแตกเก็บเลขที่คำสั่งที่ต้องกลับมาทำหลังจากทำคำสั่งในโปรแกรมย่อยนั้น ๆ เสร็จเรียบร้อยแล้ว เริ่มต้นทำงานในโปรแกรมหลัก Main สแตกจะว่าง เมื่อถึงคำสั่งที่โปรแกรม Main เรียกใช้โปรแกรมย่อย Sub1 จะทำการ push เลขที่คำสั่งของคำสั่ง St1 ลงในสแตก แล้วย้ายการทำงานไปที่โปรแกรมย่อย Sub1 จนจบ
จากภาพ อธิบายได้ว่าในสแตกเก็บเลขที่คำสั่งที่ต้องกลับมาทำหลังจากทำคำสั่งในโปรแกรมย่อยนั้น ๆ เสร็จเรียบร้อยแล้ว เริ่มต้นทำงานในโปรแกรมหลัก Main สแตกจะว่าง เมื่อถึงคำสั่งที่โปรแกรม Main เรียกใช้โปรแกรมย่อย Sub1 จะทำการ push เลขที่คำสั่งของคำสั่ง St1 ลงในสแตก แล้วย้ายการทำงานไปที่โปรแกรมย่อย Sub1 จนจบ
เมื่อต้องกลับมาทำงานในโปรแกรมหลัก Main จะทำการ pop เลขที่คำสั่งในสแตกออกมาเพื่อไปทำงานในโปรแกรมหลักที่เลขที่คำสั่งนั้นต่อไป ทำคำสั่งเรียงลำดับไปเรื่อย ๆ จนถึงคำสั่งที่เรียกใช้โปรแกรมย่อย Sub2 จะทำการ push เลขที่คำสั่งของคำสั่ง St2 ลงในสแตกซึ่งขณะนี้ว่างอยู่ แล้วไปทำงานที่โปรแกรมย่อย Sub2 ซึ่งมีการเรียกใช้โปรแกรมย่อย Sub3 จะทำการ push เลขที่คำสั่งของคำสั่ง St3 ลงในสแตกอีก แล้วจึงย้ายการทำงานไปที่โปรแกรมย่อย Sub3 ซึ่งเรียกใช้โปรแกรมย่อย Sub4 จะทำการ push เลขที่คำสั่งของคำสั่ง St4 ลงในสแตก แล้วไปทำงานที่โปรแกรมย่อย Sub4
 ในการเขียนโปรแกรมคอมพิวเตอร์ด้วยภาษาระดับสูงคำสั่งที่เป็นนิพจน์คณิตศาสตร์จะเขียนอยู่ในรูปแบบของนิพจน์ Infix นั่นคือเครื่องหมายคำนวณจะอยู่ตรงกลางระหว่างตัวแปรหรือค่าที่จะถูกนำมาคำนวณด้วย การคำนวณค่าในนิพจน์รูปแบบนี้ ตัวแปลภาษาต้องทำการตรวจสอบนิพจน์จากซ้ายไปขวา เพื่อหาเครื่องหมายหรือตัวดำเนินการที่ต้องคำนวณก่อนจึงจะเริ่มคำนวณให้ แล้วทำแบบนี้ซ้ำ ๆ กันจนกว่าจะคำนวณเครื่องหมายครบทุกตัว ซึ่งการทำงานค่อนข้างช้าและไม่สะดวกในการคำนวณ
ในการเขียนโปรแกรมคอมพิวเตอร์ด้วยภาษาระดับสูงคำสั่งที่เป็นนิพจน์คณิตศาสตร์จะเขียนอยู่ในรูปแบบของนิพจน์ Infix นั่นคือเครื่องหมายคำนวณจะอยู่ตรงกลางระหว่างตัวแปรหรือค่าที่จะถูกนำมาคำนวณด้วย การคำนวณค่าในนิพจน์รูปแบบนี้ ตัวแปลภาษาต้องทำการตรวจสอบนิพจน์จากซ้ายไปขวา เพื่อหาเครื่องหมายหรือตัวดำเนินการที่ต้องคำนวณก่อนจึงจะเริ่มคำนวณให้ แล้วทำแบบนี้ซ้ำ ๆ กันจนกว่าจะคำนวณเครื่องหมายครบทุกตัว ซึ่งการทำงานค่อนข้างช้าและไม่สะดวกในการคำนวณ
 ขั้นตอนวิธีในการเขียนโปรแกรมแปลงนิพจน์ Infix ไปเป็นนิพจน์ Postfix
ขั้นตอนวิธีในการเขียนโปรแกรมแปลงนิพจน์ Infix ไปเป็นนิพจน์ Postfix



 ในการคำนวณค่านิพจน์โพสฟิกซ์ที่แปลงมาเรียบร้อยแล้ว ตัวแปลภาษาจะทำการคำนวณโดยใช้โครงสร้างสแตกช่วยอีกเช่นกัน ซึ่งวิธีการคำนวณค่ามีลำดับขั้นตอนดังต่อไปนี้
ในการคำนวณค่านิพจน์โพสฟิกซ์ที่แปลงมาเรียบร้อยแล้ว ตัวแปลภาษาจะทำการคำนวณโดยใช้โครงสร้างสแตกช่วยอีกเช่นกัน ซึ่งวิธีการคำนวณค่ามีลำดับขั้นตอนดังต่อไปนี้
(1) อ่านตัวอักษรในนิพจน์โพสฟิกซ์จากซ้ายไปขวาทีละตัวอักษร แล้วทำข้อ 2
(2) ถ้าเป็นตัวถูกดำเนินการ ให้ทำการพุชตัวถูกดำเนินการนั้นลงในสแตก แล้วกลับไปอ่านตัวอักษรใหม่เข้ามา ในข้อ 1
(3) ถ้าเป็นตัวดำเนินการ ให้ทำการพ็อปค่าจากสแตก 2 ค่า โดยตัวแรกเป็นตัวถูกดำเนินการตัวที่ 2 และตัวต่อมาเป็นตัวถูกดำเนินการตัวที่ 1
(4) ทำการคำนวณ ตัวถูกดำเนินการที่ 1 ด้วย ตัวถูกดำเนินการที่ 2 โดยใช้ตัวดำเนินการในข้อ 3
(5) ทำการพุชผลลัพธ์ที่ได้จากการคำนวณในข้อ 4 ลงในสแตก
(6) ถ้าตัวอักษรในนิพจน์โพสฟิกซ์ยังอ่านไม่หมดให้กลับไปทำข้อ1 ถ้าหมดแล้วจบการทำงาน
 ขั้นตอนที่ 2
ขั้นตอนที่ 2
 ขั้นตอนที่ 3
ขั้นตอนที่ 3
 ขั้นตอนที่ 4
ขั้นตอนที่ 4 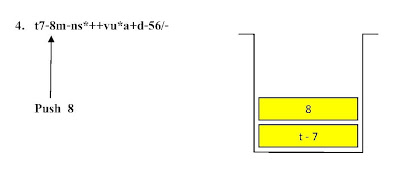 ขั้นตอนที่ 5
ขั้นตอนที่ 5
 ขั้นตอนที่ 6
ขั้นตอนที่ 6  ขั้นตอนที่ 7
ขั้นตอนที่ 7 ขั้นตอนที่ 8
ขั้นตอนที่ 8
 ขั้นตอนที่ 9
ขั้นตอนที่ 9
 ขั้นตอนที่ 10
ขั้นตอนที่ 10
 ขั้นตอนที่ 11
ขั้นตอนที่ 11
 ขั้นตอนที่ 12
ขั้นตอนที่ 12
 ขั้นตอนที่ 13
ขั้นตอนที่ 13
 ขั้นตอนที่ 14
ขั้นตอนที่ 14
 ขั้นตอนที่ 15
ขั้นตอนที่ 15
 ขั้นตอนที่ 16
ขั้นตอนที่ 16
 ขั้นตอนที่ 17
ขั้นตอนที่ 17
 ขั้นตอนที่ 18
ขั้นตอนที่ 18
 ขั้นตอนที่ 19
ขั้นตอนที่ 19
 ขั้นตอนที่ 20
ขั้นตอนที่ 20
 ขั้นตอนที่ 21
ขั้นตอนที่ 21

การแทนที่ข้อมูลของแสตก ทำได้ 2 วิธี คือ
1. การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์ ซึ่งเป็นการจัดสรรเนื้อที่หน่วยความจำแบบไดนามิก นั้นคือ หน่วยความจำจะถูกจัดสรรเมื่อมีการขอใช้จริง ๆ ระหว่างการประมวลผลโปรแกรมผ่านตัวแปรชนิด pointer
2. การแทนที่ของมูลของสแตกแบบอะเรย์ ซึ่งเป็นการจัดสรรเนื้อที่หน่วยความจำแบบสแตติก นั้นคือ จะมีการกำหนดขนาดของสแตกล่วงหน้าว่าจะมีขนาดเท่าใดและจะมีการจัดสรรเนื้อที่หน่วยความจำให้เลย
การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์ ประกอบด้วย 2 ส่วน คือ
1. Head Node ประกอบด้วย top pointer และจำนวนสมาชิกมนสแตก(Count)
1. Head Node ประกอบด้วย top pointer และจำนวนสมาชิกมนสแตก(Count)
2. Data Node ประกอบด้วย Data และ Pointer ที่ชี้ไปยังข้อมูลตัวต่อไป การดำเนินการเกี่ยวกับสแตก1. Create stack จัดสรรหน่วยความจำให้แก่ head node และส่งค่าตำแหน่งที่ชี้ไปยัง Head ของสแตกกลับมา
2. Push stack โดยทั่วไปจะกระทำที่ต้นลิสต์ซึ่งถือว่าเป็นตำแหน่งโหนดบนสุดของสแตกหรือเป็นตำแหน่งที่พุชโหนดเข้าไปในสแตกหลังสุด เมื่อมีการพุชโหนดใหม่ลงในสแตกก็จะต้องปรับค่าพอยน์เตอร์ของโหนดใหม่ชี้ไปที่โหนดบนสุดในขณะนั้น และถ้า top เป็นพอยน์เตอร์ชี้ที่ตำแหน่งโหนดบนสุดในสแตก ให้ทำการปรับพอยน์เตอร์ top ชี้ไปที่โหนดใหม่ที่ทำการพุชลงไปแทน
2. Push stack โดยทั่วไปจะกระทำที่ต้นลิสต์ซึ่งถือว่าเป็นตำแหน่งโหนดบนสุดของสแตกหรือเป็นตำแหน่งที่พุชโหนดเข้าไปในสแตกหลังสุด เมื่อมีการพุชโหนดใหม่ลงในสแตกก็จะต้องปรับค่าพอยน์เตอร์ของโหนดใหม่ชี้ไปที่โหนดบนสุดในขณะนั้น และถ้า top เป็นพอยน์เตอร์ชี้ที่ตำแหน่งโหนดบนสุดในสแตก ให้ทำการปรับพอยน์เตอร์ top ชี้ไปที่โหนดใหม่ที่ทำการพุชลงไปแทน
3. Pop stack โหนดแรกที่จะถูกพ็อปออกมาคือโหนดที่อยู่บนสุดหรือโหนดแรกของลิงค์ลิสต์นั่นเอง ก่อนที่จะทำการพ็อปโหนดต้องตรวจสอบก่อนว่าสแตกว่างหรือไม่ โดยตรวจสอบจากค่าพอยน์เตอร์ที่ชี้ตำแหน่งโหนดบนสุดของสแตก ถ้ามีค่าเป็นนัลแสดงว่า สแตกว่าง และถ้าสแตกไม่ว่างก็สามารถทำการพ็อปโหนดออกจากสแตกได้
4. Stack top เรียกใช้รายการข้อมูลที่อยู่บนสุดของ stack (เป็นการคัดลอกโดยไม่มีการลบข้อมูลออกจากสแตก)
5. Empty stack ตรวจสอบว่า stack ว่างเปล่าหรือไม่ ถ้าไม่มีข้อมูลสแตกเหลืออยู่ เราก็ไม่สามารถทำการ Pop สแตกได้ ในกรณีเช่นนี้เรียกว่า "สแตกว่าง" (Stack Underflow) โดยการตรวจสอบว่าสแตกว่างหรือไม่ เราจะตรวจสอบตัวชี้สแตกว่าเท่ากับ 0 หรือ null หรือไม่ ถ้าเท่ากับ 0 แสดงว่าสแตกว่าง จึงไม่สามารถดึงข้อมูลออกจากสแตกได้
6. Full stack ตรวจสอบว่า stack เต็มหรือไม่ ถ้าไม่มีที่ว่างเหลืออยู่ เราก็จะไม่สามารถทำการ Push สแตกได้ ในกรณีเช่นนี้เราเรียกว่า "สแตกเต็ม" (Stack Overflow) โดยการตรวจสอบว่าสแตกเต็มหรือไม่ เราจะใช้ตัวชี้สแตก (Stack pointer) มาเปรียบเทียบกับค่าสูงสุดของสแตก (Max stack) หากตัวชี้สแตกมีค่าเท่ากับค่าสูงสุดของสแตกแล้ว แสดงว่าไม่มีที่ว่างให้ข้อเก็บข้อมูลอีก
7. Stack count ส่งค่าจำนวนรายการในสแตก หรือเป็นการนับจำนวนสมาชิกในสแตก
8. Destroy stack คืนหน่วยความจำของทุก node ในสแตกให้ระบบ หรือเป็นการลบข้อมูลทั้งหมดที่อยู่ในสแตก
5. Empty stack ตรวจสอบว่า stack ว่างเปล่าหรือไม่ ถ้าไม่มีข้อมูลสแตกเหลืออยู่ เราก็ไม่สามารถทำการ Pop สแตกได้ ในกรณีเช่นนี้เรียกว่า "สแตกว่าง" (Stack Underflow) โดยการตรวจสอบว่าสแตกว่างหรือไม่ เราจะตรวจสอบตัวชี้สแตกว่าเท่ากับ 0 หรือ null หรือไม่ ถ้าเท่ากับ 0 แสดงว่าสแตกว่าง จึงไม่สามารถดึงข้อมูลออกจากสแตกได้
6. Full stack ตรวจสอบว่า stack เต็มหรือไม่ ถ้าไม่มีที่ว่างเหลืออยู่ เราก็จะไม่สามารถทำการ Push สแตกได้ ในกรณีเช่นนี้เราเรียกว่า "สแตกเต็ม" (Stack Overflow) โดยการตรวจสอบว่าสแตกเต็มหรือไม่ เราจะใช้ตัวชี้สแตก (Stack pointer) มาเปรียบเทียบกับค่าสูงสุดของสแตก (Max stack) หากตัวชี้สแตกมีค่าเท่ากับค่าสูงสุดของสแตกแล้ว แสดงว่าไม่มีที่ว่างให้ข้อเก็บข้อมูลอีก
7. Stack count ส่งค่าจำนวนรายการในสแตก หรือเป็นการนับจำนวนสมาชิกในสแตก
8. Destroy stack คืนหน่วยความจำของทุก node ในสแตกให้ระบบ หรือเป็นการลบข้อมูลทั้งหมดที่อยู่ในสแตก
การแทนที่ข้อมูลของสแตกแบบอะเรย์ เนื่องจากอาร์เรย์เป็นโครงสร้างที่ต้องมีการกำหนดจองพื้นที่แน่นอน (static) จึงจำเป็นต้องมีการกำหนดขนาดพื้นที่จัดเก็บข้อมูลสูงสุดให้เหมาะสมเมื่อมีการ นำเอาข้อมูลเข้ามาก็จะนำเข้ามาจัดไว้ในอาร์เรย์แรกสุดจากนั้นจึงเรียงลำดับกัน ไปตามพื้นที่ที่กำหนด
การดำเนินการเกี่ยวกับสแตก
1. Create stack สร้าง stack head node
2. Push stack เพิ่มรายการใน stack
3. Pop stack ลบรายการใน stack
4. Stack top เรียกใช้รายการข้อมูลที่อยู่บนสุดของ stack
5. Empty stack ตรวจสอบว่า stack ว่างเปล่าหรือไม่
6. Full stack ตรวจสอบว่า stack เต็มหรือไม่
7. Stack count ส่งค่าจำนวนรายการใน stack
8. Destroy stack คืนหน่วยความจำของทุก node ใน stack ให้ระบบ
2. Push stack เพิ่มรายการใน stack
3. Pop stack ลบรายการใน stack
4. Stack top เรียกใช้รายการข้อมูลที่อยู่บนสุดของ stack
5. Empty stack ตรวจสอบว่า stack ว่างเปล่าหรือไม่
6. Full stack ตรวจสอบว่า stack เต็มหรือไม่
7. Stack count ส่งค่าจำนวนรายการใน stack
8. Destroy stack คืนหน่วยความจำของทุก node ใน stack ให้ระบบ
การประยุกต์ใช้สแตก
สแตกเป็นโครงสร้างข้อมูลที่มีประโยชน์มาก ใช้มากในงานด้านปฏิบัติการของเครื่องคอมพิวเตอร์ที่ขั้นตอนการทำงานต้องการเก็บข่าวสารอันดับแรกสุดไว้ใช้หลังสุด และข่าวสารที่เก็บเป็นอันดับล่าสุดและรอง ๆ ลงมาใช้ก่อน เช่น การทำงานของโปรแกรมแปลภาษานำไปใช้ในเรื่องของการทำงานของโปรแกรมที่เรียกใช้โปรแกรมย่อย การคำนวณนิพจน์คณิตศาสตร์ และรีเคอร์ชัน (recursion) เป็นต้น
1. การทำงานของโปรแกรมที่มีโปรแกรมย่อย
การทำงานของโปแกรมหลักที่เรียกใช้โปรแกรมย่อย และในแต่ละโปรแกรมย่อยมีการเรียกใช้โปรแกรมย่อยต่อไปอีก ลักษณะของปฏิบัติการแบบนี้ โครงสร้างข้อมูลแบบสแตกสามารถช่วยทำงานได้ โดยที่แต่ละจุดของโปรแกรมที่เรียกใช้โปรแกรมย่อยจะเก็บเลขที่ของคำสั่งถัดไปที่เครื่องต้องกลับมาทำงานไว้ในสแตก หลังจากเสร็จสิ้นการทำงานในโปรแกรมย่อยนั้นแล้ว จะทำการ popค่าเลขที่คำสั่งออกมาจากสแตก เพื่อกลับไปทำงานที่คำสั่งต่อจากคำสั่งที่เรียกใช้โปรแกรมย่อยนั้น จนกระทั่งโหนดในสแตกว่าง
จากภาพ อธิบายได้ว่าในสแตกเก็บเลขที่คำสั่งที่ต้องกลับมาทำหลังจากทำคำสั่งในโปรแกรมย่อยนั้น ๆ เสร็จเรียบร้อยแล้ว เริ่มต้นทำงานในโปรแกรมหลัก Main สแตกจะว่าง เมื่อถึงคำสั่งที่โปรแกรม Main เรียกใช้โปรแกรมย่อย Sub1 จะทำการ push เลขที่คำสั่งของคำสั่ง St1 ลงในสแตก แล้วย้ายการทำงานไปที่โปรแกรมย่อย Sub1 จนจบเมื่อต้องกลับมาทำงานในโปรแกรมหลัก Main จะทำการ pop เลขที่คำสั่งในสแตกออกมาเพื่อไปทำงานในโปรแกรมหลักที่เลขที่คำสั่งนั้นต่อไป ทำคำสั่งเรียงลำดับไปเรื่อย ๆ จนถึงคำสั่งที่เรียกใช้โปรแกรมย่อย Sub2 จะทำการ push เลขที่คำสั่งของคำสั่ง St2 ลงในสแตกซึ่งขณะนี้ว่างอยู่ แล้วไปทำงานที่โปรแกรมย่อย Sub2 ซึ่งมีการเรียกใช้โปรแกรมย่อย Sub3 จะทำการ push เลขที่คำสั่งของคำสั่ง St3 ลงในสแตกอีก แล้วจึงย้ายการทำงานไปที่โปรแกรมย่อย Sub3 ซึ่งเรียกใช้โปรแกรมย่อย Sub4 จะทำการ push เลขที่คำสั่งของคำสั่ง St4 ลงในสแตก แล้วไปทำงานที่โปรแกรมย่อย Sub4
เมื่อทำงานในโปรแกรมย่อย Sub4 เสร็จเรียบร้อยแล้วจะทำการ pop เลขที่คำสั่งในสแตกเพื่อกลับมาทำงานต่อในโปรแกรมย่อย Sub3 นั่นคือทำคำสั่ง St4 ไปจนกระทั่งเสร็จสิ้นในโปรแกรมย่อยนี้ แล้วทำการ pop เลขที่คำสั่งที่ต้องกลับไปทำงานในโปรแกรมย่อย Sub2 โดยทำคำสั่ง St3 จนกระทั่งเสร็จสิ้นคำสั่งทั้งหมดในโปรแกรมย่อยนี้ และทำการ pop เลขที่คำสั่งที่ต้องกลับไปทำงานในโปรแกรมหลัก Main ทำคำสั่ง St2 และคำสั่งอื่น ๆ ที่เหลือตามลำดับจนกระทั่งจบโปรแกรม ซึ่งขณะนั้นสแตกจะว่าง
2. การคำนวณนิพจน์ทางคณิตศาสตร์
การเขียนนิพจน์คณิตศาสตร์เพื่อการคำนวณจะต้องคำนึงถึงลำดับความสำคัญของเครื่องหมายสำหรับการคำนวณด้วย โดยทั่วไปนิพจน์คณิตศาสตร์สามารถเขียนได้ 3 รูปแบบดังนี้
1.) นิพจน์อินฟิกซ์ (infix expression) การเขียนนิพจน์ด้วยรูปแบบนี้ ตัวดำเนินการ (operator) อยู่ตรงกลางระหว่างตัวถูกดำเนินการ (operand) 2 ตัว
2.) นิพจน์โพสฟิกซ์ (postfix expression) เป็นการเขียนนิพจน์ที่จะต้องเขียนตัวถูกดำเนินการตัวที่ 1 และตัวถูกดำเนินการตัวที่ 2 ก่อน ตามด้วยตัวดำเนินการ
3.) นิพจน์พรีฟิกซ์ (prefix expression) เป็นการเขียนนิพจน์ที่จะต้องเขียนตัวดำเนินการก่อนแล้วตามด้วยตัวถูกดำเนินการตัวที่ 1 และตัวถูกดำเนินการตัวที่ 2 ตามลำดับ
ตัวอย่างนิพจน์คณิตศาสตร์ในรูปแบบต่าง ๆ
ในการเขียนโปรแกรมคอมพิวเตอร์ด้วยภาษาระดับสูงคำสั่งที่เป็นนิพจน์คณิตศาสตร์จะเขียนอยู่ในรูปแบบของนิพจน์ Infix นั่นคือเครื่องหมายคำนวณจะอยู่ตรงกลางระหว่างตัวแปรหรือค่าที่จะถูกนำมาคำนวณด้วย การคำนวณค่าในนิพจน์รูปแบบนี้ ตัวแปลภาษาต้องทำการตรวจสอบนิพจน์จากซ้ายไปขวา เพื่อหาเครื่องหมายหรือตัวดำเนินการที่ต้องคำนวณก่อนจึงจะเริ่มคำนวณให้ แล้วทำแบบนี้ซ้ำ ๆ กันจนกว่าจะคำนวณเครื่องหมายครบทุกตัว ซึ่งการทำงานค่อนข้างช้าและไม่สะดวกในการคำนวณดังนั้นเพื่อแก้ปัญหานี้ การแปลคำสั่งที่เป็นการคำนวณนิพจน์คณิตศาสตร์ ตัวแปลภาษาจะทำการแปลงนิพจน์ Infix ให้อยู่ในรูปแบบที่ช่วยให้การคำนวณนิพจน์สะดวกและรวดเร็วขึ้น โดยแปลงให้อยู่ในรูปแบบของนิพจน์ Postfix ซึ่งตัวดำเนินการอยู่ข้างหลังตัวถูกดำเนินการทั้งสองเสมอ
สำหรับแนวคิดในการเขียนโปรแกรมเพื่อเปลี่ยนนิพจน์ Infix ไปเป็นนิพจน์ Postfix ของตัวแปลภาษา ใช้เทคนิคของการจัดเก็บข้อมูลในโครงสร้างสแตกเข้ามาช่วย โดยการพิจารณานิพจน์ Infix ทีละตัวอักษรจากซ้ายไปขวา และย้ายตัวอักษรเหล่านั้นไปเป็นตัวอักษรในนิพจน์ Postfix ทีละตัว ส่วนตัวดำเนินการจะถูกนำไปเก็บไว้ในสแตก โดยกำหนดค่าของตัวดำเนินการวงเล็บเปิด และวงเล็บปิด
ค่าลำดับความสำคัญของตัวดำเนินการ
ขั้นตอนวิธีในการเขียนโปรแกรมแปลงนิพจน์ Infix ไปเป็นนิพจน์ Postfix(1) อ่านตัวอักขระในนิพจน์อินฟิกซ์เข้ามาทีละตัว
(2) ถ้าเป็นตัวถูกดำเนินการ จะถูกย้ายไปเป็นตัวอักษรในนิพจน์โพสฟิกซ์
(3) ถ้าเป็นตัวดำเนินการ จะนำค่าลำดับความสำคัญของตัวดำเนินการที่อ่านเข้ามาในขณะนั้นไปเปรียบเทียบกับค่าลำดับความสำคัญของตัวดำเนินการที่อยู่บนสุดใน สแตก ดังนี้
- ถ้ามีความสำคัญมากกว่า จะถูกพุชลงในสแตก
- ถ้ามีความสำคัญน้อยกว่าหรือเท่ากัน จะต้องทำการพ็อปตัวดำเนินการที่อยู่ในสแตกขณะนั้นไปเรียงต่อกับตัวอักษรในนิพจน์โพสฟิกซ์
(4) ตัวดำเนินการที่เป็นวงเล็บปิด “)” จะไม่พุชลงในสแตก แต่มีผลให้ตัวดำเนินการอื่น ๆ ถูกพ็อปออกจากสแตกนำไปเรียงต่อกันในนิพจน์โพสฟิกซ์ จนกระทั่งเจอตัวดำเนินการวงเล็บเปิด “(” จะพ็อปวงเล็บเปิดออกจากสแตกแต่ไม่นำไปเรียงต่อ
(5) เมื่อทำการอ่านตัวอักษรในนิพจน์อินฟิกซ์หมดแล้ว ให้ทำการพ็อปตัวดำเนินการทุกตัวในสแตกนำมาเรียงต่อในนิพจน์โพสฟิกซ์ จะได้นิพจน์โพสฟิกซ์ตามที่ต้องการ
(2) ถ้าเป็นตัวถูกดำเนินการ จะถูกย้ายไปเป็นตัวอักษรในนิพจน์โพสฟิกซ์
(3) ถ้าเป็นตัวดำเนินการ จะนำค่าลำดับความสำคัญของตัวดำเนินการที่อ่านเข้ามาในขณะนั้นไปเปรียบเทียบกับค่าลำดับความสำคัญของตัวดำเนินการที่อยู่บนสุดใน สแตก ดังนี้
- ถ้ามีความสำคัญมากกว่า จะถูกพุชลงในสแตก
- ถ้ามีความสำคัญน้อยกว่าหรือเท่ากัน จะต้องทำการพ็อปตัวดำเนินการที่อยู่ในสแตกขณะนั้นไปเรียงต่อกับตัวอักษรในนิพจน์โพสฟิกซ์
(4) ตัวดำเนินการที่เป็นวงเล็บปิด “)” จะไม่พุชลงในสแตก แต่มีผลให้ตัวดำเนินการอื่น ๆ ถูกพ็อปออกจากสแตกนำไปเรียงต่อกันในนิพจน์โพสฟิกซ์ จนกระทั่งเจอตัวดำเนินการวงเล็บเปิด “(” จะพ็อปวงเล็บเปิดออกจากสแตกแต่ไม่นำไปเรียงต่อ
(5) เมื่อทำการอ่านตัวอักษรในนิพจน์อินฟิกซ์หมดแล้ว ให้ทำการพ็อปตัวดำเนินการทุกตัวในสแตกนำมาเรียงต่อในนิพจน์โพสฟิกซ์ จะได้นิพจน์โพสฟิกซ์ตามที่ต้องการ
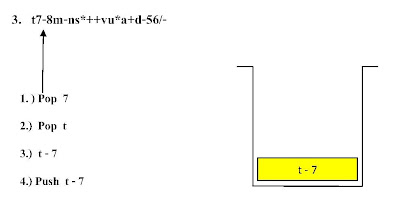
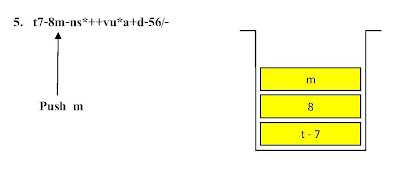
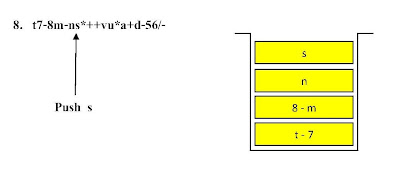
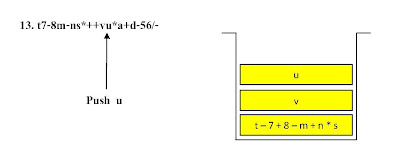
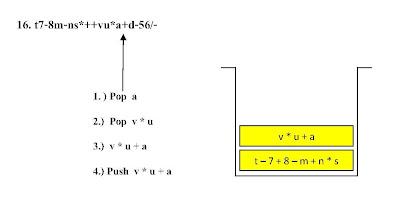
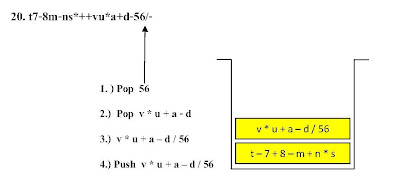
ตัวอย่าง ขั้นตอนการแปลงนิพจน์ Infix t - 7 + ( 8 - m + n * s ) - ( v * u + a - d ) / 56 ไปเป็นนิพจน์ Postfix
ในการคำนวณค่านิพจน์โพสฟิกซ์ที่แปลงมาเรียบร้อยแล้ว ตัวแปลภาษาจะทำการคำนวณโดยใช้โครงสร้างสแตกช่วยอีกเช่นกัน ซึ่งวิธีการคำนวณค่ามีลำดับขั้นตอนดังต่อไปนี้(1) อ่านตัวอักษรในนิพจน์โพสฟิกซ์จากซ้ายไปขวาทีละตัวอักษร แล้วทำข้อ 2
(2) ถ้าเป็นตัวถูกดำเนินการ ให้ทำการพุชตัวถูกดำเนินการนั้นลงในสแตก แล้วกลับไปอ่านตัวอักษรใหม่เข้ามา ในข้อ 1
(3) ถ้าเป็นตัวดำเนินการ ให้ทำการพ็อปค่าจากสแตก 2 ค่า โดยตัวแรกเป็นตัวถูกดำเนินการตัวที่ 2 และตัวต่อมาเป็นตัวถูกดำเนินการตัวที่ 1
(4) ทำการคำนวณ ตัวถูกดำเนินการที่ 1 ด้วย ตัวถูกดำเนินการที่ 2 โดยใช้ตัวดำเนินการในข้อ 3
(5) ทำการพุชผลลัพธ์ที่ได้จากการคำนวณในข้อ 4 ลงในสแตก
(6) ถ้าตัวอักษรในนิพจน์โพสฟิกซ์ยังอ่านไม่หมดให้กลับไปทำข้อ1 ถ้าหมดแล้วจบการทำงาน
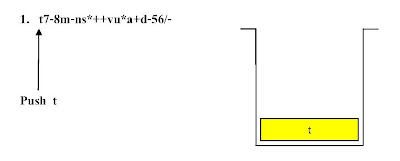
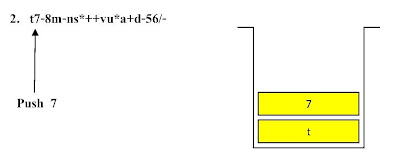
ตัวอย่าง ขั้นตอนแสดงการคำนวณค่านิพจน์ Infix จากนิพจน์ Postfix
t7-8m-ns*++vu*a+d-56/- โดยใช้โครงสร้างสแตกช่วยในการคำนวณ
ขั้นตอนที่ 1
ขั้นตอนที่ 2ขั้นตอนที่ 7ขั้นตอนที่ 17 ขั้นตอนที่ 21
สมัครสมาชิก:
บทความ (Atom)